Pre-lecture materials
Read ahead
Before class, you can prepare by reading the following materials:
Acknowledgements
Material for this lecture was borrowed and adopted from
- https://jhu-advdatasci.github.io/2019/lectures/16-intro-ml.html
- https://rafalab.github.io/dsbook/introduction-to-machine-learning.html
Learning objectives
At the end of this lesson you will:
- Be able to define machine learning (ML) and why we use it?
- Be able to recognize some misuses of ML
- Understand the parts of a ML problem
- Implement a machine learning model to classify images into two types: clouds and axes
Why machine learning?
Today we are going to be talking about machine learning. This is one of the hottest areas in all of statistics/data science. Machine learning is in the news a ton lately. Some examples include:
- Self driving cars
- Predicting poverty with satellites
- Predicting breast cancer using Google’s DeepMind AI
- Predictive policing
This is such a big idea that universities are investing major dollars to hire faculty in AI and machine learning.
On a more personal note you might be interested in AI and machine learning because it is one of the most in demand parts of being a data scientist right now. If you get really good at it you can make a lot of money.
The other really exciting reason to focus on AI and ML right now is that there is a lot of room for statistical science. Some of the biggest open problems include:
- Fairness in machine learning - tons of work on sampling, causal inference, etc.
- Morality in machine learning - studies of psychology, bias, reporting.
There are a ton more, including how to do EDA for machine learning, understanding the potential confounders and bias, understanding the predictive value of a positive and more.
What is machine learning?
Ok so machine learning is super hot right now, but what is machine learning really? You may have learned about the central dogma of statistics that you sample from a population
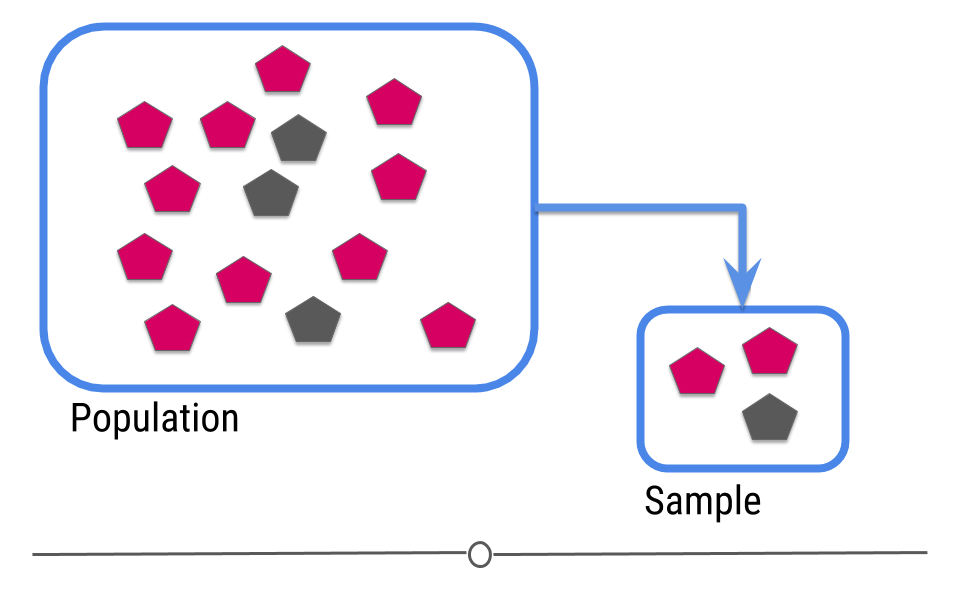
Figure 1: Central dogma of statistics: inference (part 1)
[Source]
Then you try to guess what will happen in the population from the sample.
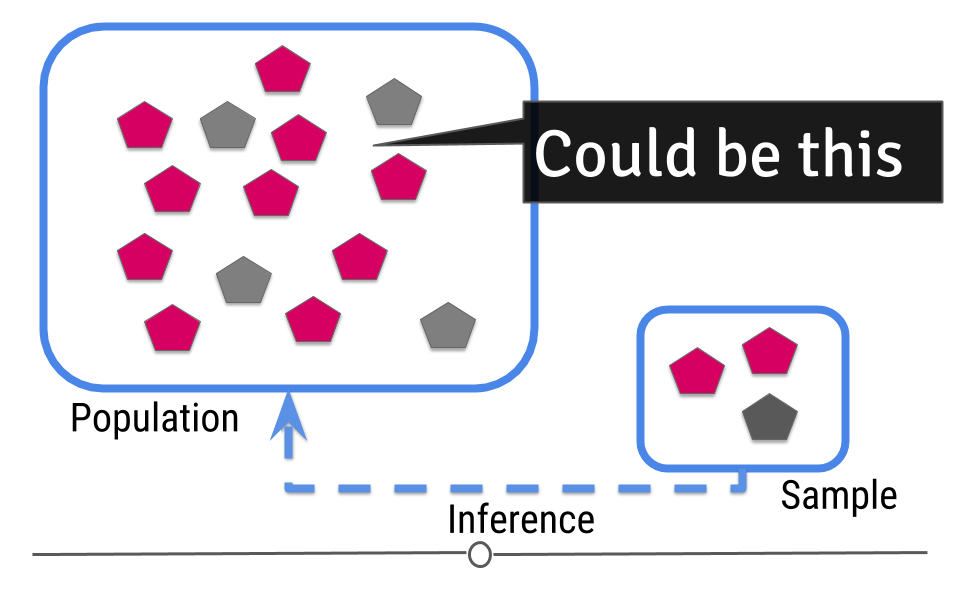
Figure 2: Central dogma of statistics: inference (part 2)
[Source]
For prediction, we have a similar sampling problem
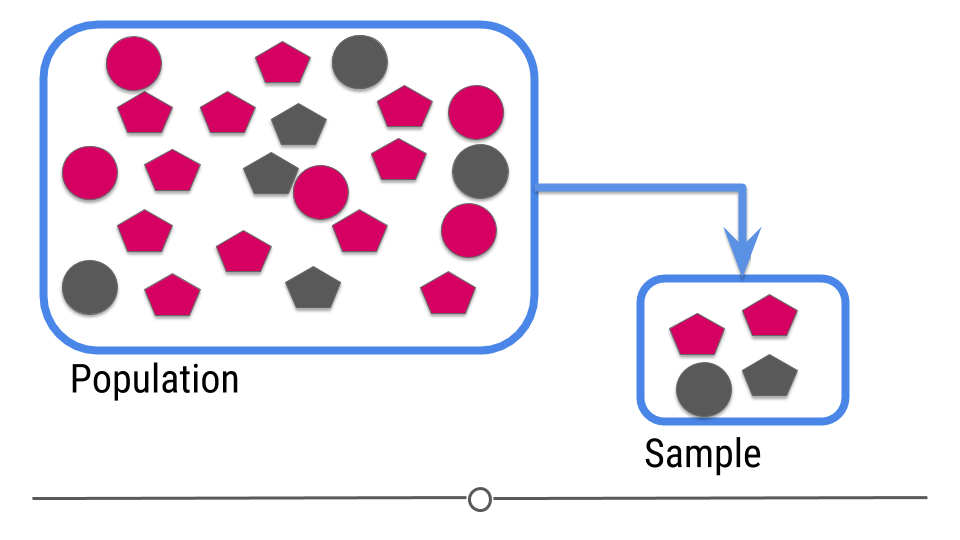
Figure 3: Central dogma of statistics: prediction (part 1)
[Source]
But now we are trying to build a rule that can be used to predict a single observation’s value of some characteristic using the others.
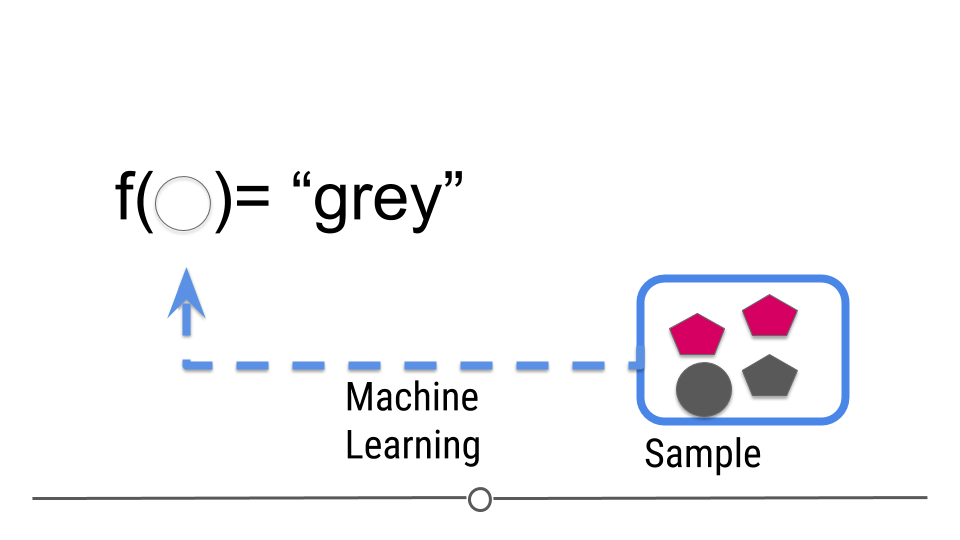
Figure 4: Central dogma of statistics: prediction (part 2)
[Source]
We can make this more concrete with a little mathematical notation.
Notation
This section borrowed from Rafa Irizarry’s excellent Data Science Book
In machine learning, data comes in the form of:
- the outcome we want to predict and
- the features that we will use to predict the outcome.
Here, we will use \(Y\) to denote the outcome and \(X_1, \dots, X_p\) to denote features. Note that features are sometimes referred to as predictors or covariates. We consider all these to be synonyms.
Goal: we want to build an algorithm that takes feature values as input and returns a prediction for the outcome when we do not know the outcome.
The machine learning approach is to train an algorithm using a dataset for which we do know the outcome to identify patterns in the training data, and then apply this algorithm in the future to make a prediction when we do not know the outcome.
Types of prediction problems
Prediction problems can be divided into categorical and continuous outcomes.
For categorical outcomes, \(Y\) can be any one of \(K\) classes. The number of classes can vary greatly across applications. For example, in the digit reader data, \(K=10\) with the classes being the digits 0, 1, 2, 3, 4, 5, 6, 7, 8, and 9. In speech recognition, the outcome are all possible words or phrases we are trying to detect. Spam detection has two outcomes: spam or not spam.
In this lesson, we denote the \(K\) categories with indexes \(k=1,\dots,K\). However, for binary data we will use \(k=0,1\) for mathematical conveniences.
The general set-up
The general set-up is as follows. We have a series of features and an unknown outcome we want to predict:
| outcome | feature_1 | feature_2 | feature_3 | feature_4 | feature_5 |
|---|---|---|---|---|---|
| ? | X_1 | X_2 | X_3 | X_4 | X_5 |
To build a model that provides a prediction for any set of values \(X_1=x_1, X_2=x_2, \dots X_5=x_5\), we collect data for which we know the outcome:
| outcome | feature_1 | feature_2 | feature_3 | feature_4 | feature_5 |
|---|---|---|---|---|---|
| Y_1 | X_1,1 | X_1,2 | X_1,3 | X_1,4 | X_1,5 |
| Y_2 | X_2,1 | X_2,2 | X_2,3 | X_2,4 | X_2,5 |
| Y_3 | X_3,1 | X_3,2 | X_3,3 | X_3,4 | X_3,5 |
| Y_4 | X_4,1 | X_4,2 | X_4,3 | X_4,4 | X_4,5 |
| Y_5 | X_5,1 | X_5,2 | X_5,3 | X_5,4 | X_5,5 |
| Y_6 | X_6,1 | X_6,2 | X_6,3 | X_6,4 | X_6,5 |
| Y_7 | X_7,1 | X_7,2 | X_7,3 | X_7,4 | X_7,5 |
| Y_8 | X_8,1 | X_8,2 | X_8,3 | X_8,4 | X_8,5 |
| Y_9 | X_9,1 | X_9,2 | X_9,3 | X_9,4 | X_9,5 |
| Y_10 | X_10,1 | X_10,2 | X_10,3 | X_10,4 | X_10,5 |
We use the notation \(\hat{Y}\) to denote the prediction. We use the term actual outcome to denote what we ended up observing. So we want the prediction \(\hat{Y}\) to match the actual outcome.
ML as an optimization problem
The central problem in machine learning can be thus written very simply as minimizing a distance metric. Let \(\hat{Y} = f(\vec{X})\) then our goal is to minimize the distance from our estimated function of the predictors to the actual value.
\[d(Y - f(\vec{X}))\]
\(d(\cdot)\) could be something as simple as the mean squared distance or something much more complex. The bulk of machine learning research in theoretical computer science and statistics departments focuses on defining different values of \(d\) and \(f\). We will talk a bit more about this in the next lesson.
The parts of an ML problem
A machine learning problem consists of a few different parts and its important to consider each one. To solve a (standard) machine learning problem you need:
- A data set to train from.
- An algorithm or set of algorithms you can use to try values of \(f\) (e.g. logistic regression, random forest, support vector machine)
- A distance metric \(d\) for measuring how close \(Y\) is to \(\hat{Y}\) (e.g. mean squared error)
- A definition of what a “good” distance is (e.g. different types of performance metrics)
While each of these components is a technical problem, there has been a ton of work addressing those technical details. The most pressing open issue in machine learning is realizing that though these are technical steps they are not objective steps.
In other words, how you choose the data, algorithm, metric, and definition of “good” says what you value and can dramatically change the results. A couple of cases where this was a big deal are:
- Machine learning for recidivism - people built ML models to predict who would re-commit a crime. But these predictions were based on historically biased data which led to biased predictions about who would commit new crimes.
- Deciding how self driving cars should act - self driving cars will have to make decisions about how to drive, who they might injure, and how to avoid accidents. Depending on our choices for \(f\) and \(d\) these might lead to wildly different kinds of self driving cars.
Try out the moralmachine to see how this looks in practice.
Example: QuickDraw!
Quick,Draw! is an online game where you are given an object to draw (like a cello, axe, airplane, etc.) and then you have to draw it with your finger. Then a pre-trained deep learning algorithm is applied to guess what kind of a drawing you have made. You can try it out here.
One interesting thing about this project and something to keep in mind if you are thinking about ways to get cool data is the exchange that Google is making here. They are giving you a fun game to play for free and in return you are giving them a ton of free data. This is the same exchange made by other successful startups:
- reCAPTCHA you click on images to prove you are a human, they give you access to a website.
- DuoLingo you practice learning words, they collect information on the way you say those words or your translations
Before going any further, we load a few R packages we will need
The main steps in a machine learning problem are:
- Question definition
- Goal setting
- Data collection
- Training/testing/validation splits
- Data exploration
- Data processing
- Model selection and fitting
- Model evaluation
We will use the Quick, Draw! dataset to discuss a few different parts of the ML process.
Start with a question
This is the most commonly missed step when developing a machine learning algorithm. ML can very easily be turned into an engineering problem. Just dump the outcome and the features into a black box algorithm and viola!
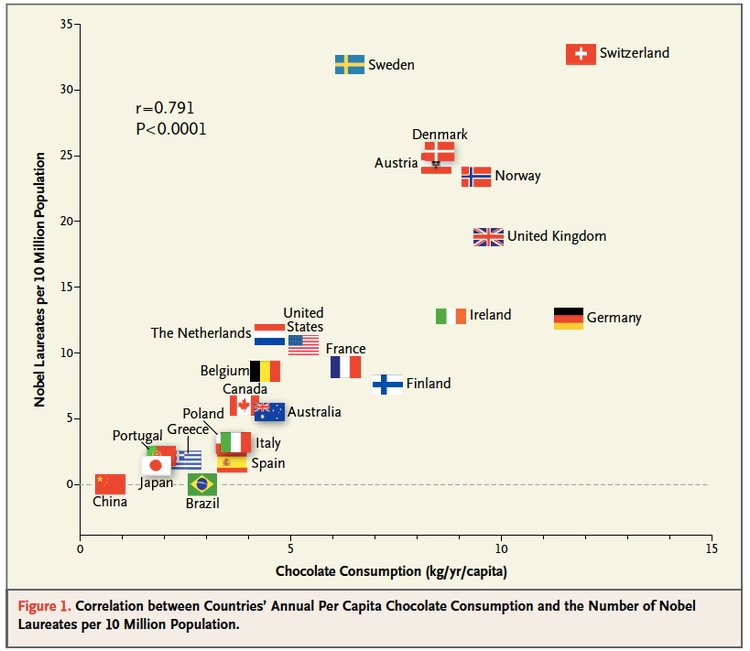
But this kind of thinking can lead to major problems. In general good ML questions:
- Have a plausible explanation for why the features predict the outcome.
- Consider potential variation in both the features and the outcome over time
- Are consistently re-evaluated on criteria 1 and 2 over time.
For example, there is a famous case where Google predicted Flu outbreaks based on search results. But the way people searched (due to changes in the algorithm, changes in culture, or other unexplained reasons) led to variation in the search terms people were using. This led to the algorithm predicting wildly badly over time.
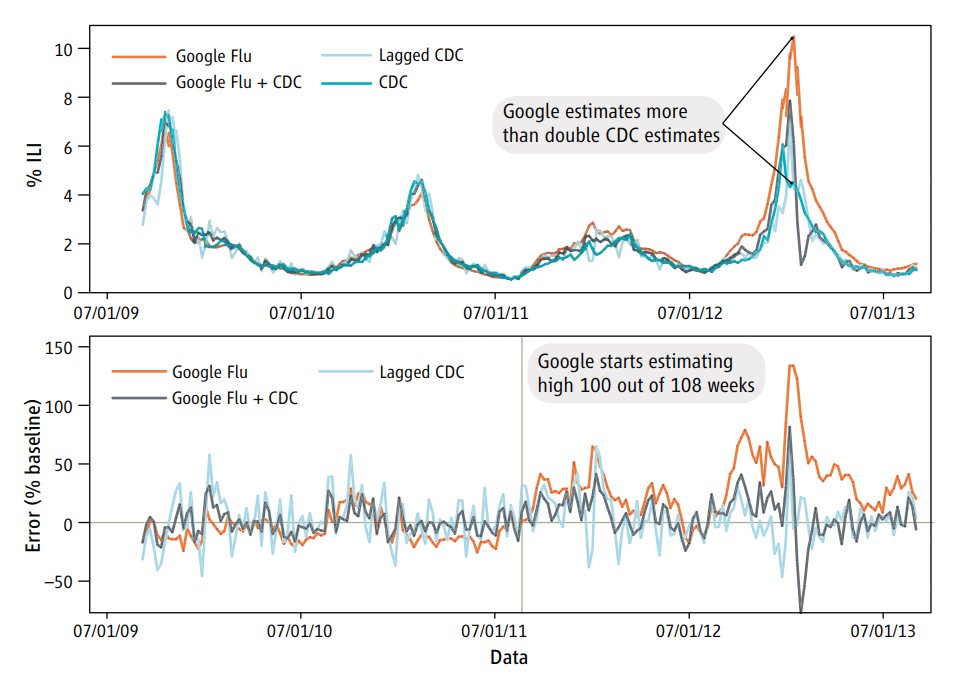
This is just one example of a spurious correlation, which is one of the big worries. In general all of the reasons for skepticism apply here.
In our QuickDraw! example, there are a ton of interesting analyses you could do with these data, but we are going to start with something simple. Can we predict from the drawing data what kind of object was drawn? To make matters even simpler we are going to just look at a couple of types of images: axes and clouds.
Goal setting
One important part of any machine learning problem is defining what success looks like. This choice very much depends on the application and what you are trying to do.
For example, when we talk about the goal in ML we are usually talking about the error rate we want to minimize and how small we want to make it. Consider for each observation we have an outcome \(y\) and a set of features \(\vec{x}\). Our goal is to create a function \(\hat{y} = \hat{f}(\vec{x})\) such that the distance, \(d(y,\hat{f}(\vec{x}))\), between the observed and the predicted \(y\) is minimized.
The two most common distances that show up in machine learning (and the ones you will always be using if you don’t change the defaults!) are:
- Root mean squared error (RMSE) - this is the most common error measure for regression (read: continuous outcome) problems.
- \(d(y,\hat{f}(\vec{x})) = \sqrt{\sum_i \left(y_i-\hat{f}(\vec{x}_i)\right)^2}\)
- Accuracy - this is the most common error measure for classification (read: factor outcomes) problems.
- \(d(y,\hat{f}(\vec{x})) = \sum_i 1\left(y=\hat{f}(\vec{x})\right)\)
Here, we are going to use simple accuracy and say that anything better than guessing is “good enough”.
But in general there are a number of other potential error measures:
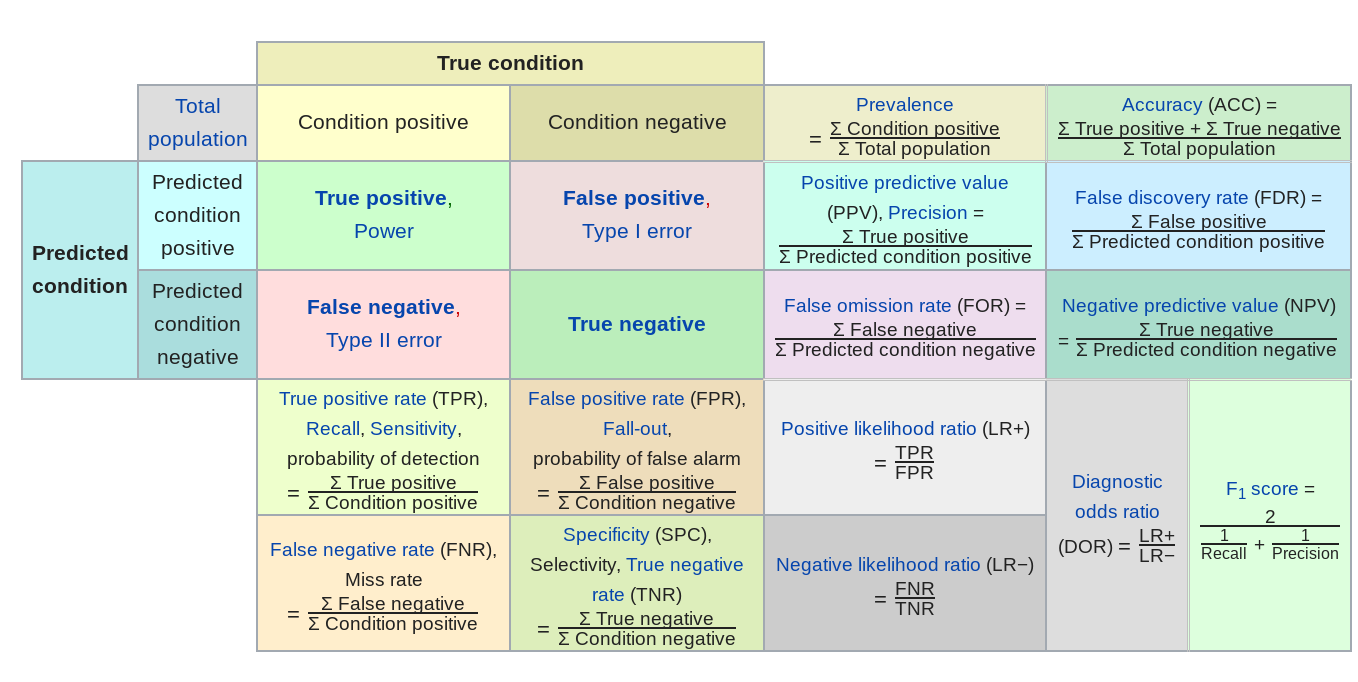
Here are a few examples of how they might be relevant.
- Predictive value of a positive - in classification if one group is much less frequent than another, then even high sensitivity/high specificity tests can produce lots of false positives (the classic example is cancer screening, but very relevant for any screening problem). So the PPV = probability that subjects with a positive screening test truly have the disease.
- Mean absolute error - in regression sometimes you want your error to be less sensitive to a few outliers (this might be true in predicting highly skewed outcomes like income or property values) and MAE can reduce the influence of those outliers.
- Specificity - when the cost of a false negative is really high compared to a false positive and you never want to miss any negatives (say for example missing a person standing in front of a self driving car)
In general, you need to spend a good amount of time thinking about what the goal is, what the tradeoff of various different errors are and then build that into your model.
Data collection
Here, we will focus on one somewhat unique issue that arises often in ML problems - the data are often huge and not sampled randomly.
Questions:
We know that a 5% random sample is better than a 5% non-random sample in measurable ways (e.g. bias, uncertainty assessment).
But is an 80% non-random sample “better” than a 5% random sample in measurable terms? 90%? 95%? 99%? (Jeremy Wu 2012)
“Which one should we trust more: a 1% survey with 60% response rate or a non-probabilistic dataset covering 80% of the population?” (Keiding and Louis, 2016, Journal of Royal Statistical Society, Series B)
There is a pretty detailed, but really good paper addressing this question by Xiao-Li Meng.
The surprising answer is that it depends! If there is correlation between the outcome value and the sampling probability even huge data sets can actually be very small in “effective sample size”. So it is worth thinking very hard about potential correlation between the outcome and the (designed or de facto) sampling scheme.
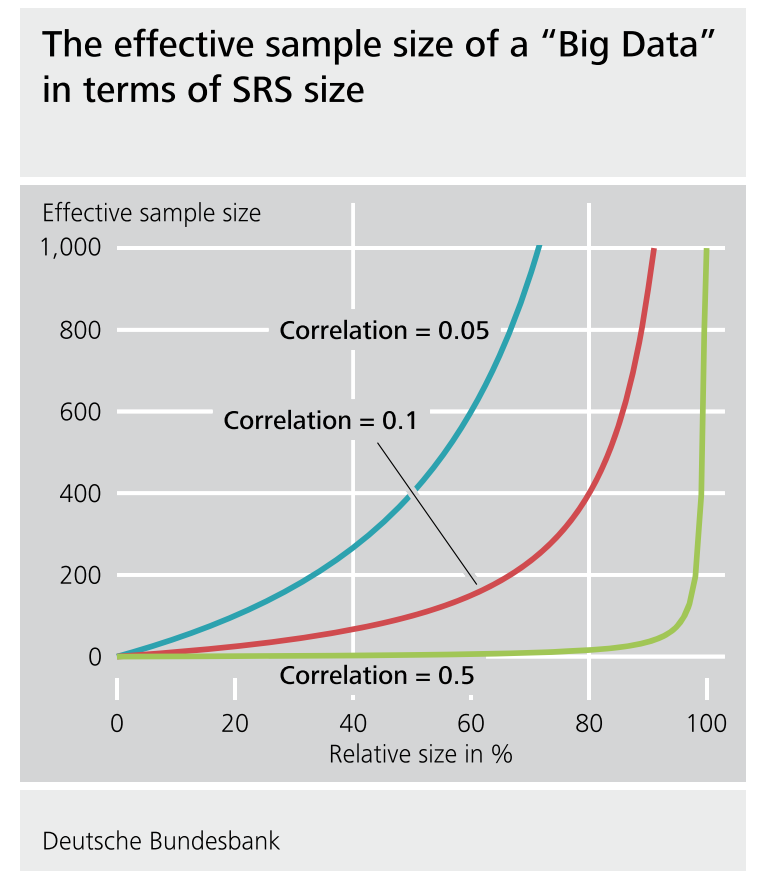
Back to quick draw
OK back to our example. Google has released some of the data from the Quick, Draw! challenge. You can either get the data in raw form or you can get some pre-processed data.
I downloaded the pre-processed data sets for clouds and axes. These data are available from Google Cloud Platform.
- Align the drawing to the top-left corner, to have minimum values of 0.
- Uniformly scale the drawing, to have a maximum value of 255.
- Resample all strokes with a 1 pixel spacing.
- Simplify all strokes using the Ramer–Douglas–Peucker algorithm (strokes are simplified) with an epsilon value of 2.0.
All these things make data easier to manage and to represent into a plot. This already represents a lot of work, but even so we still have some more pre-processing to do.
First, we are going to load some of the data into R, it comes in ndjson (new line delimited JSON) format and there are lots of drawings.
if(!file.exists(here("data", "axe.ndjson"))){
file_url_axe <- paste0("https://storage.googleapis.com/quickdraw_dataset/full/simplified/axe.ndjson")
download.file(file_url_axe,
destfile=here("data", "axe.ndjson"))
file_url_cloud <- paste0("https://storage.googleapis.com/quickdraw_dataset/full/simplified/cloud.ndjson")
download.file(file_url_cloud,
destfile=here("data", "cloud.ndjson"))
}
list.files(here("data"))
[1] "2016-07-19.csv.bz2" "axe.ndjson"
[3] "bmi_pm25_no2_sim.csv" "chicago.rds"
[5] "Chinook.sqlite" "chopped.RDS"
[7] "cloud.ndjson" "flights.csv"
[9] "maacs_sim.csv" "nycflights13"
[11] "storms_2004.csv.gz" "team_standings.csv"
[13] "tuesdata_rainfall.RDS" "tuesdata_temperature.RDS"Next, we are going to read in 100 drawings of each class using the sample_lines() function from the LaF package.
?LaF::sample_lines
We will start with the axes:
set.seed(123)
axes_json = LaF::sample_lines(here("data","axe.ndjson"), n = 100)
length(axes_json)
[1] 100And repeat for clouds:
set.seed(123)
clouds_json = LaF::sample_lines(here("data","cloud.ndjson"), n = 100)
length(clouds_json)
[1] 100Data loading and EDA
Before we talk about data exploration and processing, it is important to look at your data and think about what you find in it.
Important: I want to point out you should do this exploration only in the training set. However, in this example, we are going split the data at a later point.
If you want to know more about this concept, read about data leakage.
OK the data are not in a format we can do anything with yet. Each line is a json object:
axes_json[[1]]
[1] "{\"word\":\"axe\",\"countrycode\":\"US\",\"timestamp\":\"2017-01-23 21:25:30.06067 UTC\",\"recognized\":true,\"key_id\":\"4842320119726080\",\"drawing\":[[[69,74,75,73,70,79,98,105,111,110,70],[76,92,118,239,252,255,252,208,133,73,66]],[[70,57,20,0,28,91,107,114,115,140,134,123,116,112],[66,74,87,0,17,31,45,59,78,95,75,55,50,37]],[[45,50,48],[20,51,74]]]}"
[Source]
The next thing I did was google “quick draw data ndjson rstats”. I found a tutorial and lifted some code for processing ndjson data into data frames.
parse_drawing <- function(list){
lapply(list$drawing, function(z) {tibble(x=z[[1]], y=z[[2]])}) %>%
bind_rows(.id = "line") %>%
mutate(drawing=list$key_id, row_id=row_number())
}
What is this code doing?
drawingis a named element that we are going to work with in each of the json objectsxandycontain the coordinates for the locationsbind_rows()fromdplyris similar todo.call(rbind)in base R to bind many data frames in to one. Here the use of the.idargument is like a data frame identifier. You can think oflineas drawing a single stroke (or line) when you draw something on a page.- Finally, we add two new columns:
drawingwhich contains an ID for each drawing (key_id) androw_number()creates a tracker for each drawing.
Ok let’s try geting our first axe out:
first_axe <-
rjson::fromJSON(axes_json[[1]]) %>%
parse_drawing()
first_axe
# A tibble: 28 × 5
line x y drawing row_id
<chr> <dbl> <dbl> <chr> <int>
1 1 69 76 4842320119726080 1
2 1 74 92 4842320119726080 2
3 1 75 118 4842320119726080 3
4 1 73 239 4842320119726080 4
5 1 70 252 4842320119726080 5
6 1 79 255 4842320119726080 6
7 1 98 252 4842320119726080 7
8 1 105 208 4842320119726080 8
9 1 111 133 4842320119726080 9
10 1 110 73 4842320119726080 10
# … with 18 more rowsOk this doesn’t look like much, but we could plot it to see if it looks like an axe.
first_axe %>%
ggplot(aes(x=x, y=y)) +
geom_point() +
scale_x_continuous(limits=c(0, 255))+
scale_y_reverse(limits=c(255, 0))+
theme_minimal()
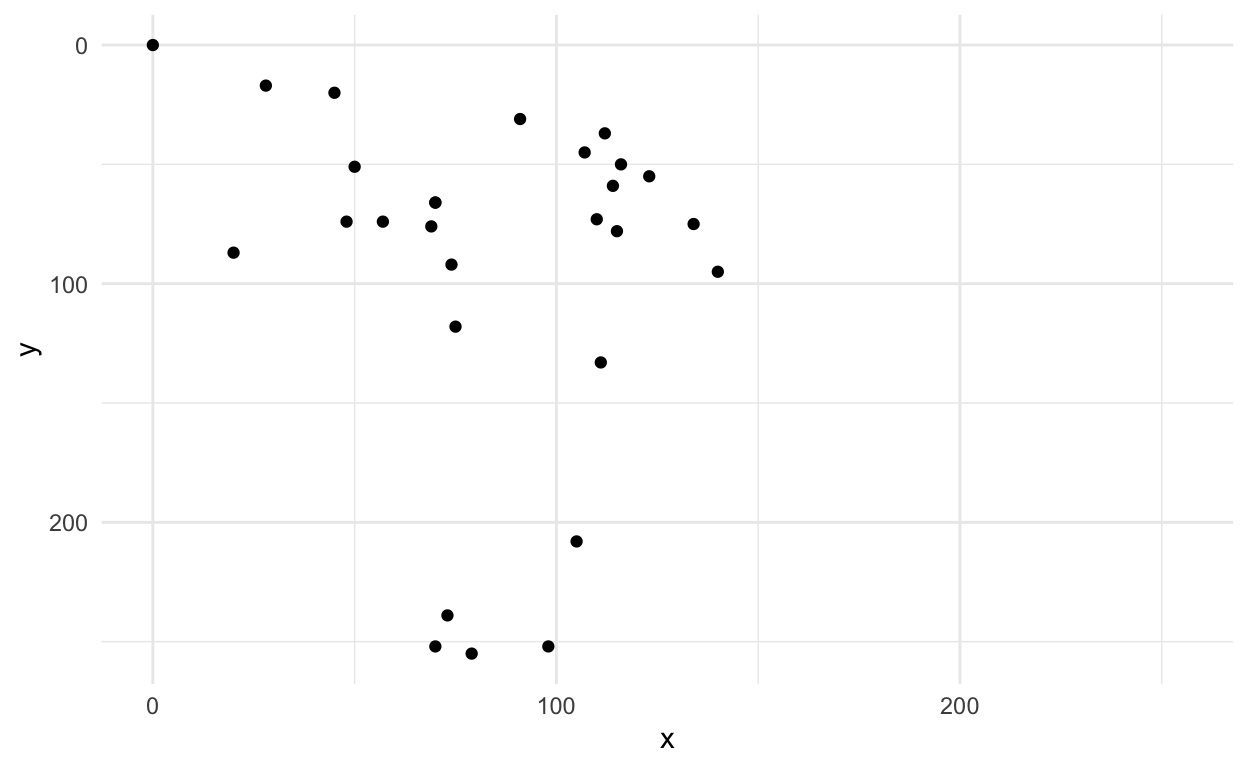
This sort of looks OK, but maybe a better way to look at it is to actually draw the lines?
Hint: check out line in the first_axe data frame and the geom_path() geom in ggplot2
?geom_path
Putting it all together
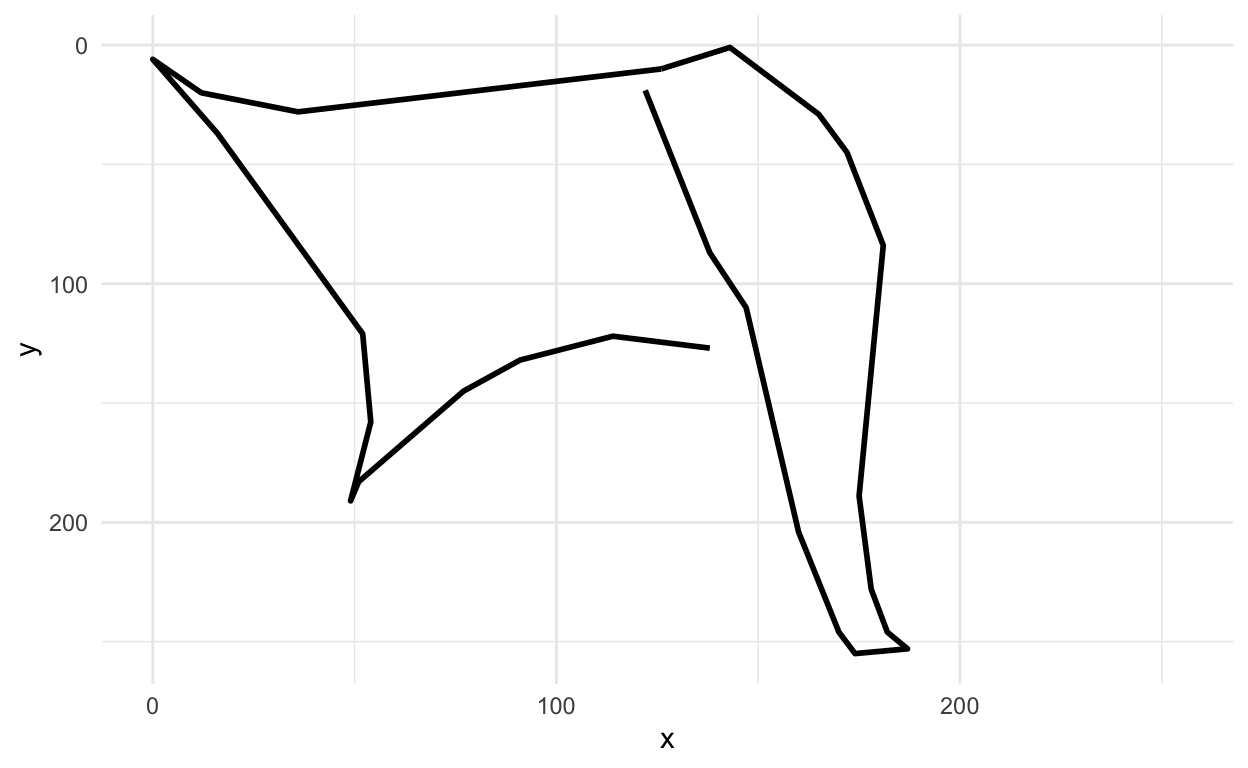
first_axe %>%
ggplot(aes(x=x, y=y)) +
geom_path(aes(group = line), lwd=1)+
scale_x_continuous(limits=c(0, 255))+
scale_y_reverse(limits=c(255, 0))+
theme_minimal()

Hey that sort of looks like an axe!
Questions:
- How many
lines are there in this drawing? - How would we filter to just draw the second line?
### try it out
OK let’s see another one.
rjson::fromJSON(axes_json[[2]]) %>%
parse_drawing() %>%
ggplot(aes(x=x, y=y)) +
geom_path(aes(group = line), lwd=1)+
scale_x_continuous(limits=c(0, 255))+
scale_y_reverse(limits=c(255, 0))+
theme_minimal()
Pro tip: If we were doing this for real, I would make plots for a large sample of these, understand the variation (and look for mislabeled drawings, messed up observations, etc.).
Next let’s look at a cloud
rjson::fromJSON(clouds_json[[1]]) %>%
parse_drawing() %>%
ggplot(aes(x=x, y=y)) +
geom_path(aes(group = line), lwd=1)+
scale_x_continuous(limits=c(0, 255))+
scale_y_reverse(limits=c(255, 0))+
theme_minimal()
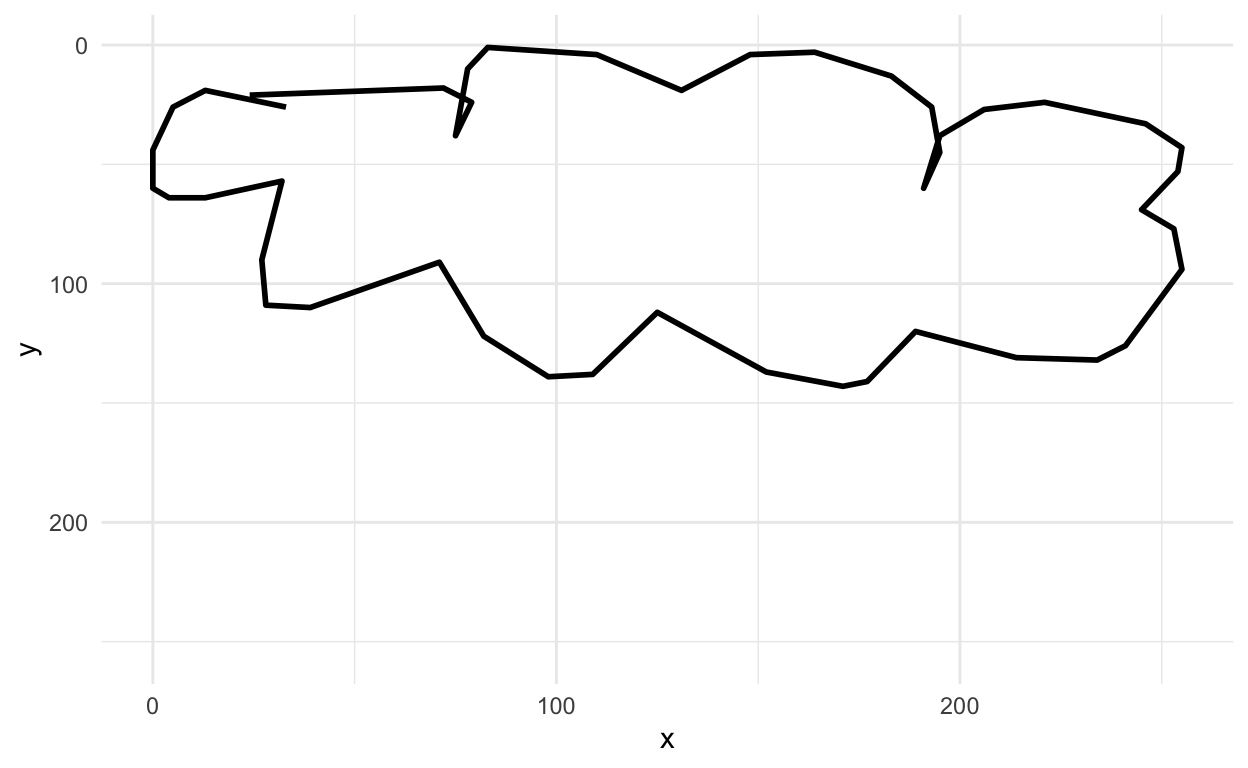
Yup, looks like a cloud! You can see how the x and y axis align in the top left corner.
Data pre-processing
Feature engineering
One of the key issues in building a model is feature engineering. Feature engineering is a step in a machine learning model where we construct the covariates (or features, \(\vec{x}\)) that you will feed into the prediction algorithms.
Unstructured data
Feature engineering is particularly important for “unstructured” data. This is:
“information that either does not have a pre-defined data model or is not organized in a pre-defined manner. Unstructured information is typically text-heavy, but may contain data such as dates, numbers, and facts as well.”
For example, we can take a pile of text (unstructured data) like this Emily Dickinson quote from the tidy text tutorial:
Convert this vector of character strings into a tibble where each row is a single character string:
text_df <-
tibble(text = text) %>%
mutate(line = row_number())
text_df
# A tibble: 4 × 2
text line
<chr> <int>
1 Because I could not stop for Death - 1
2 He kindly stopped for me - 2
3 The Carriage held but just Ourselves - 3
4 and Immortality 4And turn it into something like counts of each word:
text_df %>%
unnest_tokens(word, text) %>%
count(word)
# A tibble: 19 × 2
word n
<chr> <int>
1 and 1
2 because 1
3 but 1
4 carriage 1
5 could 1
6 death 1
7 for 2
8 he 1
9 held 1
10 i 1
11 immortality 1
12 just 1
13 kindly 1
14 me 1
15 not 1
16 ourselves 1
17 stop 1
18 stopped 1
19 the 1Now we have a table of the frequency of words in this text. But what if we repeated this process for all the text in one of Emily’s book to determine the most commonly used words from this author. And then we picked a second book from a different author, created a table of the most commonly used words from the second author.
To see an example, let’s check out this blog by Julia Silge:
https://juliasilge.com/blog/tidy-text-classification/
The first thing was to engineer the features from two books:
- Pride and Prejudice by Jane Austen
- The War of the Worlds by H. G. Wells
Let’s build a supervised machine learning model that learns the difference between text from the two authors:
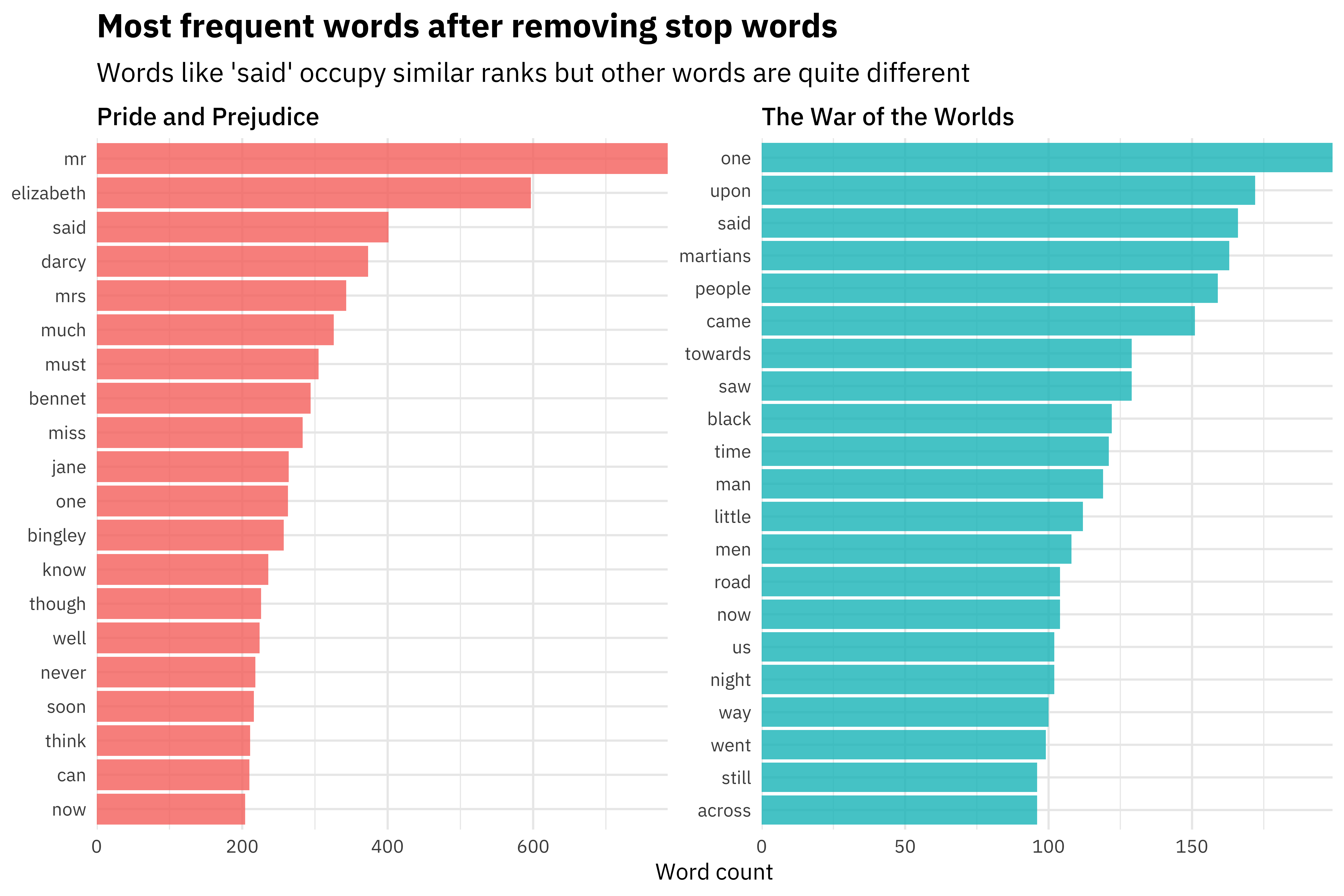
We could then use these features (where an observation is a single line of text) to build a machine learning model that learns the difference between text from Pride and Prejudice and text from The War of the Worlds.
Here are the features that are most important in the model built by Julia:
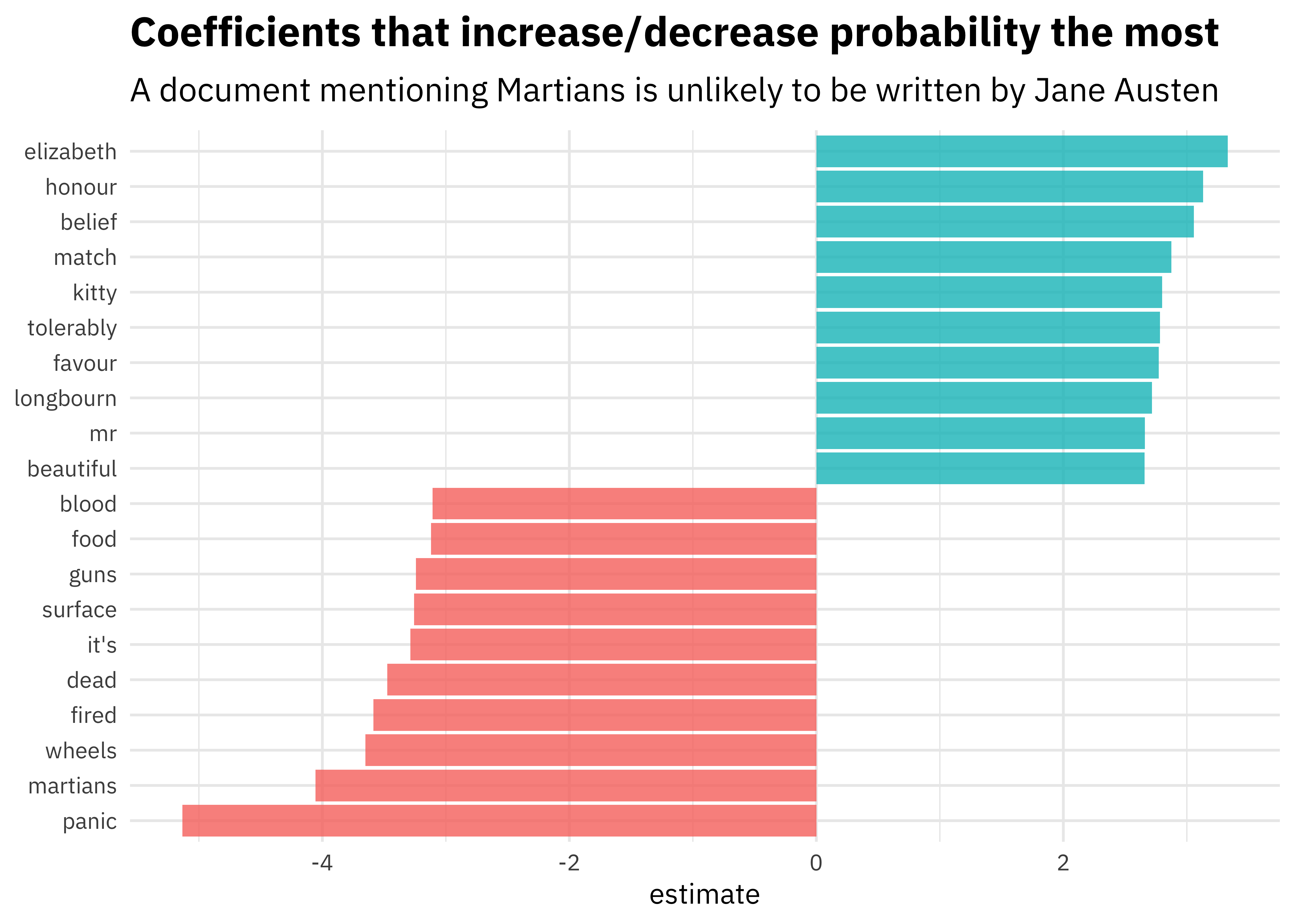
[Source]
Then, if we give the machine learning algorithm a new line of text it has not seen before, it could predict whether it came from Jane Austen or H.G. Wells.
Other types of feature engineering
If the data are continuous, you may consider other types of feature engineering:
- feature scaling: Get the features on the same scale (for e.g. Euclidean distance)
- feature transformation: Normalize the data (feature) (e.g. log transformation)
- feature construction: Create new features based on original descriptors to improve the accuracy of the predictive model (e.g. binning continuous variables to categorical variables or encoding numerical variables from categorical variables )
- feature reduction: Improve the statistical distribution and accuracy of the predictive model
Back to quick draw
Back to our data above, e.g.
rjson::fromJSON(axes_json[[1]]) %>%
parse_drawing()
# A tibble: 28 × 5
line x y drawing row_id
<chr> <dbl> <dbl> <chr> <int>
1 1 69 76 4842320119726080 1
2 1 74 92 4842320119726080 2
3 1 75 118 4842320119726080 3
4 1 73 239 4842320119726080 4
5 1 70 252 4842320119726080 5
6 1 79 255 4842320119726080 6
7 1 98 252 4842320119726080 7
8 1 105 208 4842320119726080 8
9 1 111 133 4842320119726080 9
10 1 110 73 4842320119726080 10
# … with 18 more rowsA bunch of data processing has been done for us, but the data are not quite ready to be fed into an algorithm yet.
To do that, we would need a data frame with each row equal to one drawing and each column equal to one feature for that drawing, with an extra column for the drawing output (e.g. cloud or axe).
To do this, we need to think about creating a standardized grid for storing our data on. However, the choice of grid is decision left up to us (you can think of this as feature engineering).
Another thing we might want is for our data to be of a manageable size (again the choice of how we do this is another decision left up to us – more feature engineering).
Points on a regular grid
Let’s start by creating a regular grid of 256 x and y values.
grid_dat = as_tibble(expand.grid(x = 1:256,y=1:256))
dim(grid_dat)
[1] 65536 2head(grid_dat)
# A tibble: 6 × 2
x y
<int> <int>
1 1 1
2 2 1
3 3 1
4 4 1
5 5 1
6 6 1Now we could make each x, y value be a grid point with a join (this is overkill)
# A tibble: 65,537 × 5
x y line drawing row_id
<dbl> <dbl> <chr> <chr> <int>
1 1 1 <NA> <NA> NA
2 2 1 <NA> <NA> NA
3 3 1 <NA> <NA> NA
4 4 1 <NA> <NA> NA
5 5 1 <NA> <NA> NA
6 6 1 <NA> <NA> NA
7 7 1 <NA> <NA> NA
8 8 1 <NA> <NA> NA
9 9 1 <NA> <NA> NA
10 10 1 <NA> <NA> NA
# … with 65,527 more rows# A tibble: 2 × 2
`is.na(line)` n
<lgl> <int>
1 FALSE 27
2 TRUE 65510We see most of the lines are NA. Let’s add an indicator of whether a particular value is NA or not.
[1] 4124 4909 7771 9328 11371 12660 12850 13947 14962 16710 16711
[12] 18543 18737 18746 19079 19270 19828 22037 23371 24205 30028 33904
[23] 53098 61002 64327 64355 65104grid_axe[which(grid_axe$pixel == 1),]
# A tibble: 27 × 6
x y line drawing row_id pixel
<dbl> <dbl> <chr> <chr> <int> <dbl>
1 28 17 2 4842320119726080 16 1
2 45 20 3 4842320119726080 26 1
3 91 31 2 4842320119726080 17 1
4 112 37 2 4842320119726080 25 1
5 107 45 2 4842320119726080 18 1
6 116 50 2 4842320119726080 24 1
7 50 51 3 4842320119726080 27 1
8 123 55 2 4842320119726080 23 1
9 114 59 2 4842320119726080 19 1
10 70 66 1 4842320119726080 11 1
# … with 17 more rowsData set of a manageable size
Let’s try subsampling this down to a smaller image.
We will use Hmisc::cut2() to cut a numeric variable into intervals. It’s similar to cut() in base R, but left endpoints are inclusive and labels are of the form [lower, upper), except that last interval is [lower,upper].
However, we will use levels.mean=TRUE to make the new categorical vector have levels attribute that is the group means of grid_axe$x instead of interval endpoint labels.
grid_axe$xgroup = Hmisc::cut2(grid_axe$x, g=16, levels.mean=TRUE) # g is number of quantile groups
grid_axe
# A tibble: 65,537 × 7
x y line drawing row_id pixel xgroup
<dbl> <dbl> <chr> <chr> <int> <dbl> <fct>
1 1 1 <NA> <NA> NA 0 " 9.000"
2 2 1 <NA> <NA> NA 0 " 9.000"
3 3 1 <NA> <NA> NA 0 " 9.000"
4 4 1 <NA> <NA> NA 0 " 9.000"
5 5 1 <NA> <NA> NA 0 " 9.000"
6 6 1 <NA> <NA> NA 0 " 9.000"
7 7 1 <NA> <NA> NA 0 " 9.000"
8 8 1 <NA> <NA> NA 0 " 9.000"
9 9 1 <NA> <NA> NA 0 " 9.000"
10 10 1 <NA> <NA> NA 0 " 9.000"
# … with 65,527 more rowstable(grid_axe$xgroup)
9.000 25.500 41.500 57.500 72.999 88.500 104.500 120.500
4352 4096 4096 4096 3841 4096 4096 4096
136.500 152.500 168.500 184.500 200.500 216.500 232.500 248.500
4096 4096 4096 4096 4096 4096 4096 4096 Let’s do the same for y
grid_axe$ygroup = Hmisc::cut2(grid_axe$y,g=16,levels.mean=TRUE)
grid_axe
# A tibble: 65,537 × 8
x y line drawing row_id pixel xgroup ygroup
<dbl> <dbl> <chr> <chr> <int> <dbl> <fct> <fct>
1 1 1 <NA> <NA> NA 0 " 9.000" " 9.000"
2 2 1 <NA> <NA> NA 0 " 9.000" " 9.000"
3 3 1 <NA> <NA> NA 0 " 9.000" " 9.000"
4 4 1 <NA> <NA> NA 0 " 9.000" " 9.000"
5 5 1 <NA> <NA> NA 0 " 9.000" " 9.000"
6 6 1 <NA> <NA> NA 0 " 9.000" " 9.000"
7 7 1 <NA> <NA> NA 0 " 9.000" " 9.000"
8 8 1 <NA> <NA> NA 0 " 9.000" " 9.000"
9 9 1 <NA> <NA> NA 0 " 9.000" " 9.000"
10 10 1 <NA> <NA> NA 0 " 9.000" " 9.000"
# … with 65,527 more rowsNow I can convert these to numbers so we’ll have them later
grid_axe <-
grid_axe %>%
mutate(xgroup = as.numeric(as.character(xgroup)) - 7.5) %>%
mutate(ygroup = as.numeric(as.character(ygroup)) - 7.5)
table(grid_axe$xgroup)
1.5 18 34 50 65.499 81 97 113 129 145
4352 4096 4096 4096 3841 4096 4096 4096 4096 4096
161 177 193 209 225 241
4096 4096 4096 4096 4096 4096 grid_axe
# A tibble: 65,537 × 8
x y line drawing row_id pixel xgroup ygroup
<dbl> <dbl> <chr> <chr> <int> <dbl> <dbl> <dbl>
1 1 1 <NA> <NA> NA 0 1.5 1.5
2 2 1 <NA> <NA> NA 0 1.5 1.5
3 3 1 <NA> <NA> NA 0 1.5 1.5
4 4 1 <NA> <NA> NA 0 1.5 1.5
5 5 1 <NA> <NA> NA 0 1.5 1.5
6 6 1 <NA> <NA> NA 0 1.5 1.5
7 7 1 <NA> <NA> NA 0 1.5 1.5
8 8 1 <NA> <NA> NA 0 1.5 1.5
9 9 1 <NA> <NA> NA 0 1.5 1.5
10 10 1 <NA> <NA> NA 0 1.5 1.5
# … with 65,527 more rowsNow we can average within groups of pixels to get a smaller image
# A tibble: 256 × 3
# Groups: xgroup [16]
xgroup ygroup pixel
<dbl> <dbl> <dbl>
1 1.5 1.5 0
2 1.5 18 0
3 1.5 34 0
4 1.5 50 0
5 1.5 65.5 0
6 1.5 81 0
7 1.5 97 0
8 1.5 113 0
9 1.5 129 0
10 1.5 145 0
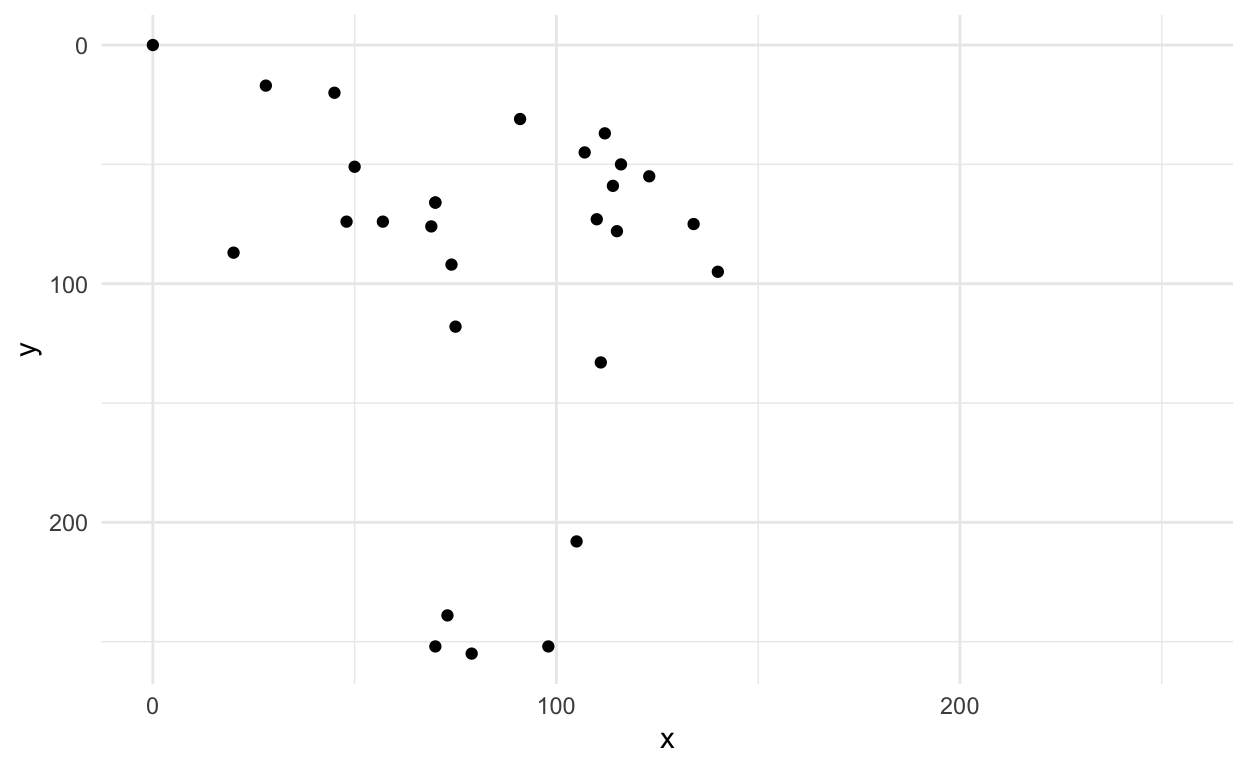
# … with 246 more rowsRemember this was our original axe
first_axe %>%
ggplot(aes(x=x, y=y)) +
geom_point() +
scale_x_continuous(limits=c(0, 255))+
scale_y_reverse(limits=c(255, 0))+
theme_minimal()
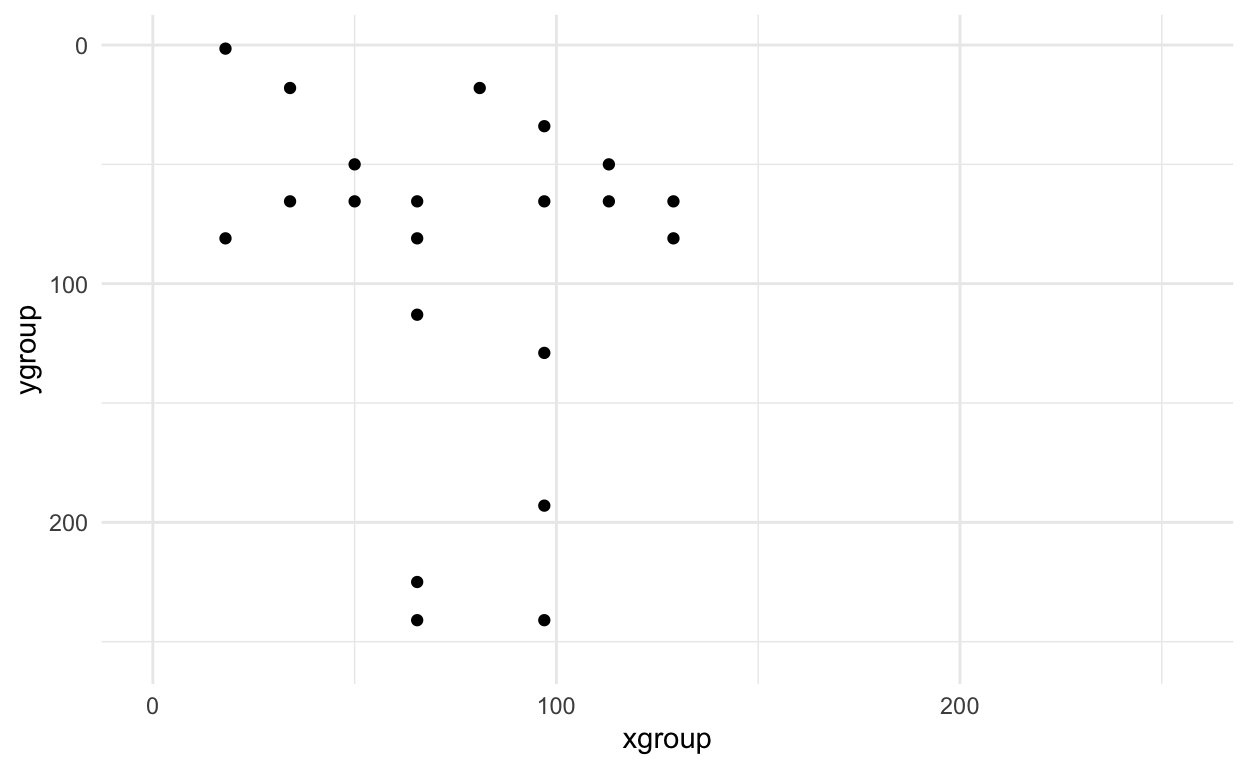
Now we can look at the small version - it looks similar - whew! :)
small_axe %>%
filter(pixel > 0) %>%
ggplot(aes(x = xgroup, y = ygroup)) +
geom_point() +
scale_x_continuous(limits=c(0, 255))+
scale_y_reverse(limits=c(255, 0))+
theme_minimal()
Doing this for all axes and clouds
Now let’s do this for all axes and clouds
img_dat = tibble(pixel=NA, type=NA, drawing=NA, pixel_number=NA)
#First axes
for(i in 1:100){
tmp_draw = rjson::fromJSON(axes_json[[i]]) %>% parse_drawing()
grid_draw = left_join(grid_dat,tmp_draw) %>%
mutate(pixel = ifelse(is.na(line),0,1))
grid_draw$xgroup = cut2(grid_draw$x,g=16,levels.mean=TRUE)
grid_draw$ygroup = cut2(grid_draw$y,g=16,levels.mean=TRUE)
small_draw = grid_draw %>%
mutate(xgroup = as.numeric(as.character(xgroup)) - 7.5) %>%
mutate(ygroup = as.numeric(as.character(ygroup)) - 7.5) %>%
group_by(xgroup,ygroup) %>%
summarise(pixel=mean(pixel)) %>% ungroup() %>%
select(pixel) %>%
mutate(type="axe",drawing=i,pixel_number=row_number())
img_dat = img_dat %>% bind_rows(small_draw)
}
#Then clouds
for(i in 1:100){
tmp_draw = rjson::fromJSON(clouds_json[[i]]) %>% parse_drawing()
grid_draw = left_join(grid_dat,tmp_draw) %>%
mutate(pixel = ifelse(is.na(line),0,1))
grid_draw$xgroup = cut2(grid_draw$x,g=16,levels.mean=TRUE)
grid_draw$ygroup = cut2(grid_draw$y,g=16,levels.mean=TRUE)
small_draw = grid_draw %>%
mutate(xgroup = as.numeric(as.character(xgroup)) - 7.5) %>%
mutate(ygroup = as.numeric(as.character(ygroup)) - 7.5) %>%
group_by(xgroup,ygroup) %>%
summarise(pixel=mean(pixel)) %>% ungroup() %>%
select(pixel) %>%
mutate(type="cloud",drawing=i,pixel_number=row_number())
img_dat = img_dat %>% bind_rows(small_draw)
}
Now let’s look at this new data frame
img_dat = img_dat[-1,]
img_dat
# A tibble: 51,200 × 4
pixel type drawing pixel_number
<dbl> <chr> <int> <int>
1 0 axe 1 1
2 0 axe 1 2
3 0 axe 1 3
4 0 axe 1 4
5 0 axe 1 5
6 0 axe 1 6
7 0 axe 1 7
8 0 axe 1 8
9 0 axe 1 9
10 0 axe 1 10
# … with 51,190 more rowsWe can use pivot_wider() and viola we finally have a processed data set!
library(tidyr)
img_final <-
img_dat %>%
pivot_wider(names_from = pixel_number, values_from = pixel)
names(img_final) = c("type", "drawing", paste0("pixel", 1:256))
img_final
# A tibble: 200 × 258
type drawing pixel1 pixel2 pixel3 pixel4 pixel5 pixel6
<chr> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 axe 1 0 0 0 0 0 0
2 axe 2 0 0.00368 0.00368 0 0 0
3 axe 3 0 0.00368 0 0 0 0.00368
4 axe 4 0.00391 0 0.00391 0 0 0
5 axe 5 0 0 0 0.00368 0 0
6 axe 6 0 0 0.00391 0 0 0
7 axe 7 0 0 0.00781 0 0 0
8 axe 8 0 0 0.00391 0 0 0
9 axe 9 0.00781 0 0.00391 0 0 0
10 axe 10 0.0117 0 0 0.00391 0 0
# … with 190 more rows, and 250 more variables: pixel7 <dbl>,
# pixel8 <dbl>, pixel9 <dbl>, pixel10 <dbl>, pixel11 <dbl>,
# pixel12 <dbl>, pixel13 <dbl>, pixel14 <dbl>, pixel15 <dbl>,
# pixel16 <dbl>, pixel17 <dbl>, pixel18 <dbl>, pixel19 <dbl>,
# pixel20 <dbl>, pixel21 <dbl>, pixel22 <dbl>, pixel23 <dbl>,
# pixel24 <dbl>, pixel25 <dbl>, pixel26 <dbl>, pixel27 <dbl>,
# pixel28 <dbl>, pixel29 <dbl>, pixel30 <dbl>, pixel31 <dbl>, …Splitting into training, testing, validation
Now that we have our data processed an important step is to break the data up into a training, testing, and validation set.
In general, people use these words in different ways:

I actually like this proposal to call them “training, tuning, and testing” sets, so let’s use that.
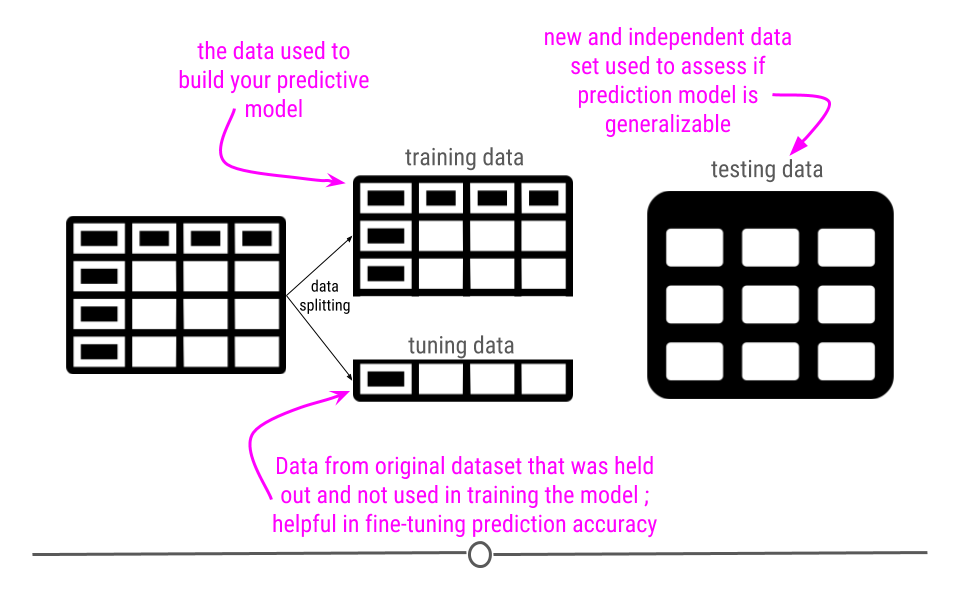
But the reason for this splitting is that we want to avoid being overly optimistic or “overfitting” on the training data. That would prevent us from predicting well on new samples.
Overfitting
Here is a funny example from XKCD to illustrate overfitting

The basic idea is that if you keep adding predictors, the model will “predict well” on the data you have, no matter how well we expect it to do in the future.
The key thing to keep in mind is that there are two types of variation in any data set, the “signal” and the “noise”. Using math notation, imagine that the “real” model for a data set is:
\[y_i = \underbrace{g(\vec{x}_i)}_{signal} + \underbrace{e_i}_{noise}\]
Let’s use a concrete, simple example:
\[y_i = \underbrace{x^2}_{signal} + \underbrace{e_i}_{noise}\]
Imagine we want to “learn” a model of the form:
\[y_i = \sum_{k=1}^K b_k g_k(x_i) + e_i\]
Then, the model
- Fits if \(\sum_{k=1}^K b_k g_k(x) \approx x^2\).
- Overfits if \(\sum_{k=1}^K b_k g_k(x) \approx x^2 + e_i\)
- Underfits if \(\sum_{k=1}^K b_k g_k(x) \neq x^2\)
Let’s simulate from the example above to give a better idea:
dat = tibble(x = rnorm(30),y=rnorm(30,mean=x^2))
ggplot(dat,aes(x=x,y=y)) +
geom_point() +
theme_minimal()
Now let’s fit three models to this data. One that underfits, one that fits, and one that overfits.
# To make plotting easier later
dat = dat %>%
arrange(x)
lm_under = lm(y ~ x,data=dat)
# using natural splines to model a non-linear relationship with
# piecewise cubic polynomials
# can specify df (degrees of freedom) and then ns() chooses (df - 1)
# interior knots at certain quantiles of x
lm_fits = lm(y ~ ns(x,df=2),data=dat)
lm_over = lm(y ~ ns(x,df=10),data=dat)
# add_predictions() is from the modelr R package
dat_pred = dat %>%
add_predictions(lm_fits,"fits") %>%
add_predictions(lm_under,"under") %>%
add_predictions(lm_over,"over")
dat_pred = dat_pred %>%
pivot_longer(-c(x,y),
names_to = "fit_type",
values_to = "fit")
dat_pred %>%
ggplot(aes(x=x,y=y)) +
geom_point() +
geom_line(aes(x=x, y=fit,
group=fit_type,
color=fit_type)) +
theme_minimal()
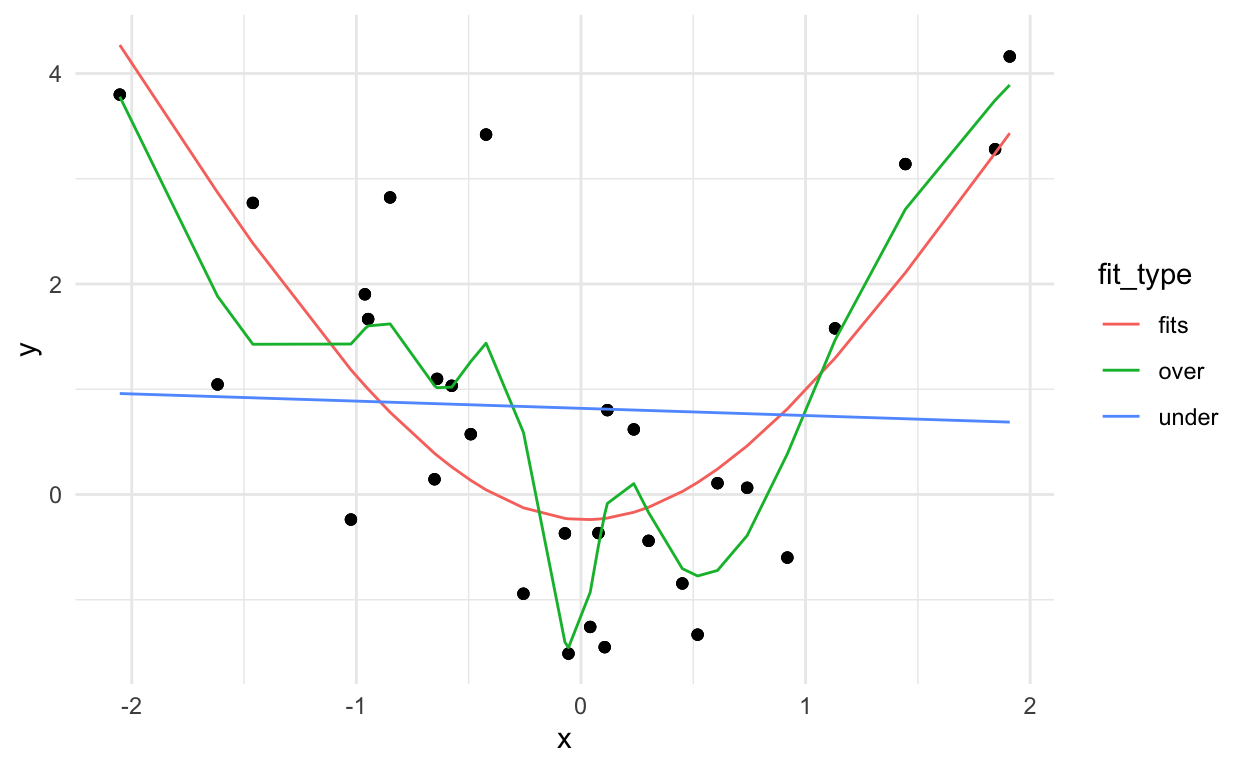
You can kind of see that the blue line misses the signal, the red line fits pretty well, and the green line seems to capture a little too much of the noise.
If we look at the errors (here: mean squared error between \(Y\) and \(\hat{Y}\)) of each approach we get:
dat_pred %>%
mutate(res2 = (y - fit)^2) %>%
group_by(fit_type) %>%
summarise(rmse = sqrt(sum(res2)))
# A tibble: 3 × 2
fit_type rmse
<chr> <dbl>
1 fits 6.10
2 over 4.58
3 under 9.12It looks like the overfitting approach was best, but we can probably guess that won’t work on a new data set:
dat2 = tibble(x = rnorm(30), y = rnorm(30,mean=x^2))
dat2_pred = dat2 %>%
add_predictions(lm_fits,"fits") %>%
add_predictions(lm_under,"under") %>%
add_predictions(lm_over,"over")
dat2_pred <-
dat2_pred %>%
pivot_longer(-c(x,y), names_to = "fit_type", values_to = "fit")
dat2_pred %>%
ggplot(aes(x=x,y=y)) +
geom_point() +
theme_minimal() +
geom_line(aes(x=x, y=fit,
group=fit_type,
color=fit_type))
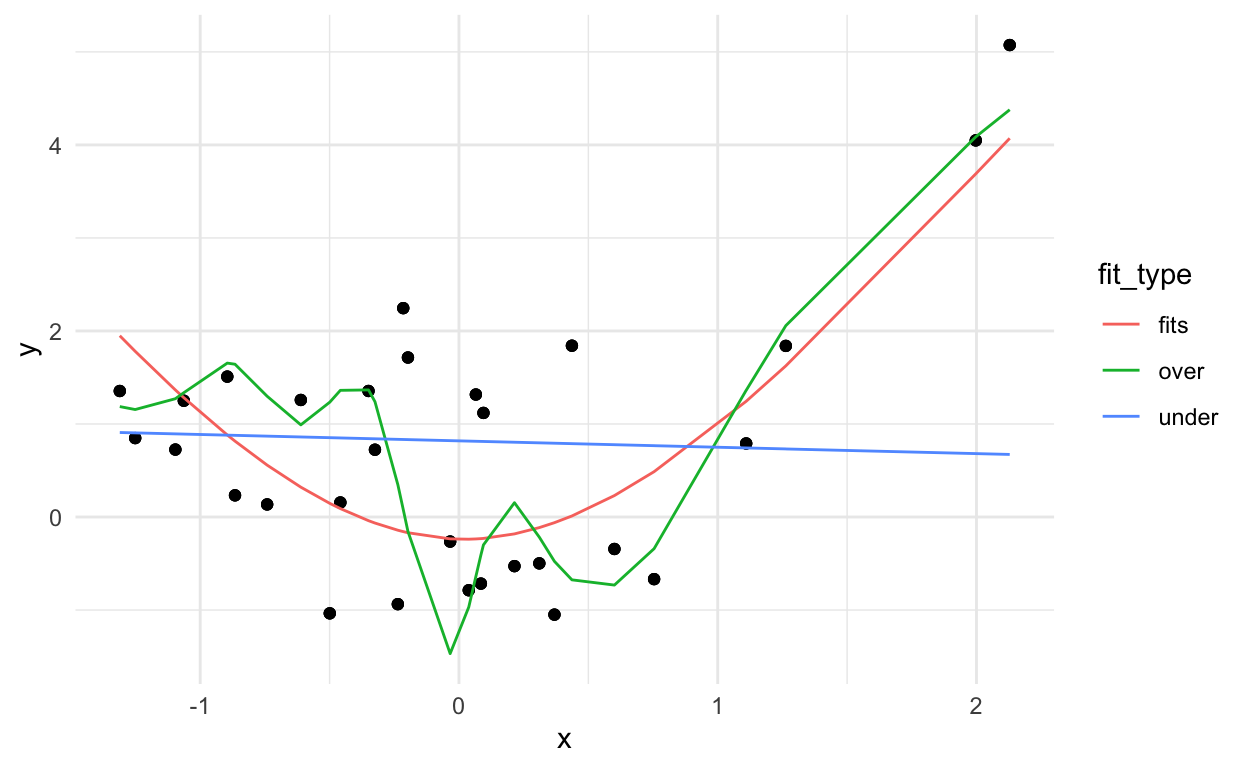
Where the best model will be the one that captures the signal (which remains fixed) and not the noise (which changes).
dat2_pred %>%
mutate(res2 = (y - fit)^2) %>%
group_by(fit_type) %>%
summarise(rmse = sqrt(sum(res2)))
# A tibble: 3 × 2
fit_type rmse
<chr> <dbl>
1 fits 5.45
2 over 6.03
3 under 7.86Bias variance tradeoff
Overfitting is related to another general concept - the bias variance trade-off.
In general, the more predictors you have in a model the lower the bias but the higher the variance. This is called the “bias-variance trade-off”.
To see an example of this, let’s fit these models in 100 simulated data sets and see what the models predict for a x value of 0 (the prediction should equal 0).
over = under = fits = rep(0,100)
ex_dat = tibble(x=0)
for(i in 1:100){
new_dat = tibble(x = rnorm(30),y=rnorm(30,mean=x^2))
lm_under = lm(y ~ x,data=new_dat)
lm_fits = lm(y ~ ns(x,df=2),data=new_dat)
lm_over = lm(y ~ ns(x,df=10),data=new_dat)
over[i] = predict(lm_over,ex_dat)
under[i] = predict(lm_under,ex_dat)
fits[i] = predict(lm_fits,ex_dat)
}
results = tibble(over,under,fits) %>%
pivot_longer(names_to = "type",
values_to = "prediction",
c(over,under,fits))
The results show that when we fit the exact right model we do best (no surprise there!).
When the model is too complex we get low bias (values predicted close to zero on average) but high variance.
When the model is not complex enough we get high bias (values predicted away from zero) but low variance.
results %>%
ggplot(aes(y=prediction,group=type,fill=type)) +
geom_boxplot() +
theme_minimal()
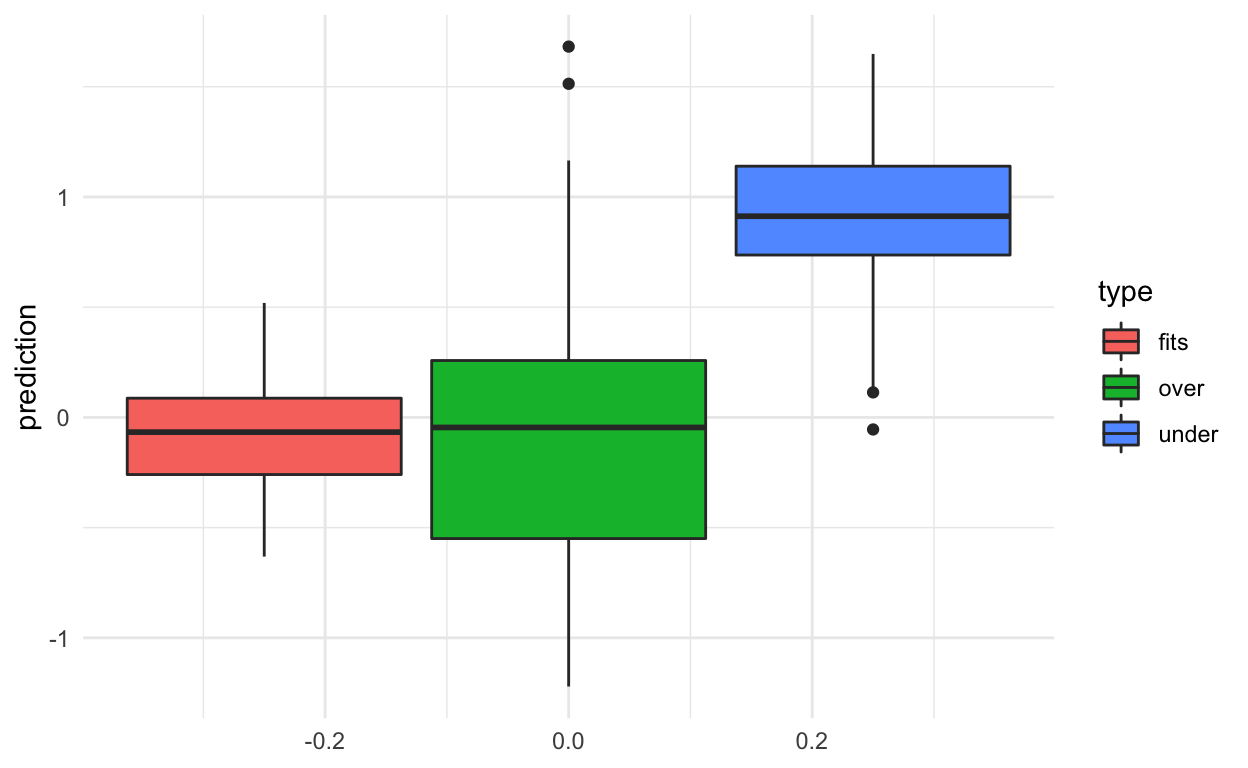
In general, you will not know the “true” model, so the goal is to try to pick a model that gives a happy medium on the bias-variance trade-off (of course depending on your goals).
What do you do in training/tuning/testing
Imagine we have broken the data into three components:
- \(X_{tr}\) = training data
- \(X_{tu}\) = tuning data
- \(X_{te}\) = testing data
Now we need to “fit” the model. Let’s briefly talk about what this means.
A machine learning model has two parts:
- An algorithm
- A set of parameters
The algorithm would be something like regression models with splines:
\[y_i = \sum_{k=1}^K b_k g_k(x_i) + e_i\]
And the parameters would be the choices of \(b_k\), \(g_k\) and \(K\). These parameters are “fit” by estimating them from the training data (or fixing them in advance).
- Training - In the training set, you try different algorithms, estimate their parameters, and see which one works best.
- Tuning - Once you have settled on a single algorithm (or a small set of algorithms), you use the tuning set to estimate which parameters work best outside of the training sample you originally built on.
- Testing - Once your algorithm and all your parameters for your model are fixed, then you apply that fitted model just one time to the test set to evaluate the error rate for your model realistically.
Cross validation
Within the training set you are choosing between algorithms and parameters, but like we saw above, if you use the whole training set you may end up overfitting to the noise in the data. So when selecting algorithms and parameters, you need some way to make sure you don’t just pick the algorithm that is most overfit.
The typical way people do this is by cross-validation (figure borrowed from Rafa’s Data Science Book).
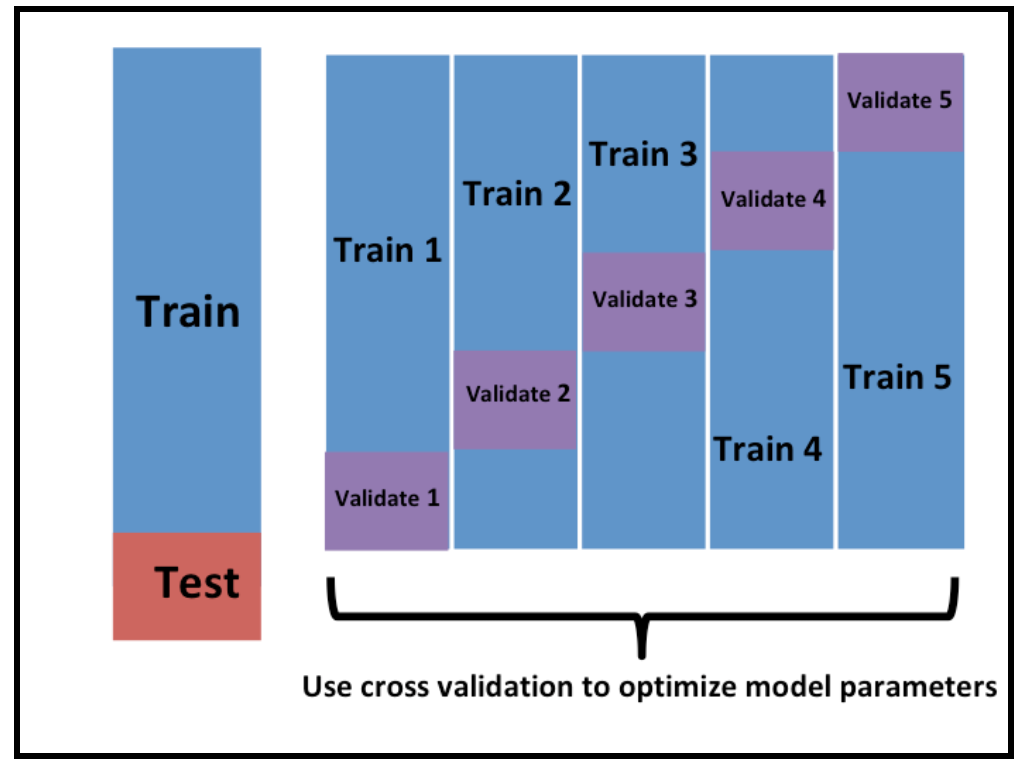
\(K\)-fold cross validation just splits up the training set into \(K\) pieces. You build the model on part of the training data and apply it to the rest. This gives you a better evaluation of the out of sample error - so will allow you to rank models in a better way.
You can also use something called the bootstrap. But you need to adjust for the fact that the training and testing sets are random samples.
Back to quick draw
Here we are going to simply use training and testing using the createDataPartition() function in the caret package with the argument p being the percentages of data that goes into training:
train_set = createDataPartition(y = img_final$type, p = 0.5,
list=FALSE)
train_dat = img_final[train_set,]
test_dat = img_final[-train_set,]
:::keyideas
Important!!!!: We leave the test set alone until the very end!
and for those in the back
it’s worth repeating: We leave the test set alone until the very end!
:)
Model selection and fitting
A lot of machine learning is considering variations on the equation:
\[d(y,f(\vec{x}))\]
where the things we are varying is the choice of distance metric \(d()\) which we have already discussed (e.g. mean squared error, accuracy, PPV).
We have talked a lot less about varying \(f()\) which is the most common topic for many machine learning books. Here, we will briefly review a couple of the key algorithms.
The first thing to keep in mind is that with well engineered features, often simple algorithms due almost as well as more advanced algorithms.
The other thing to keep in mind with these types of algorithms is that there are often important tradeoffs.
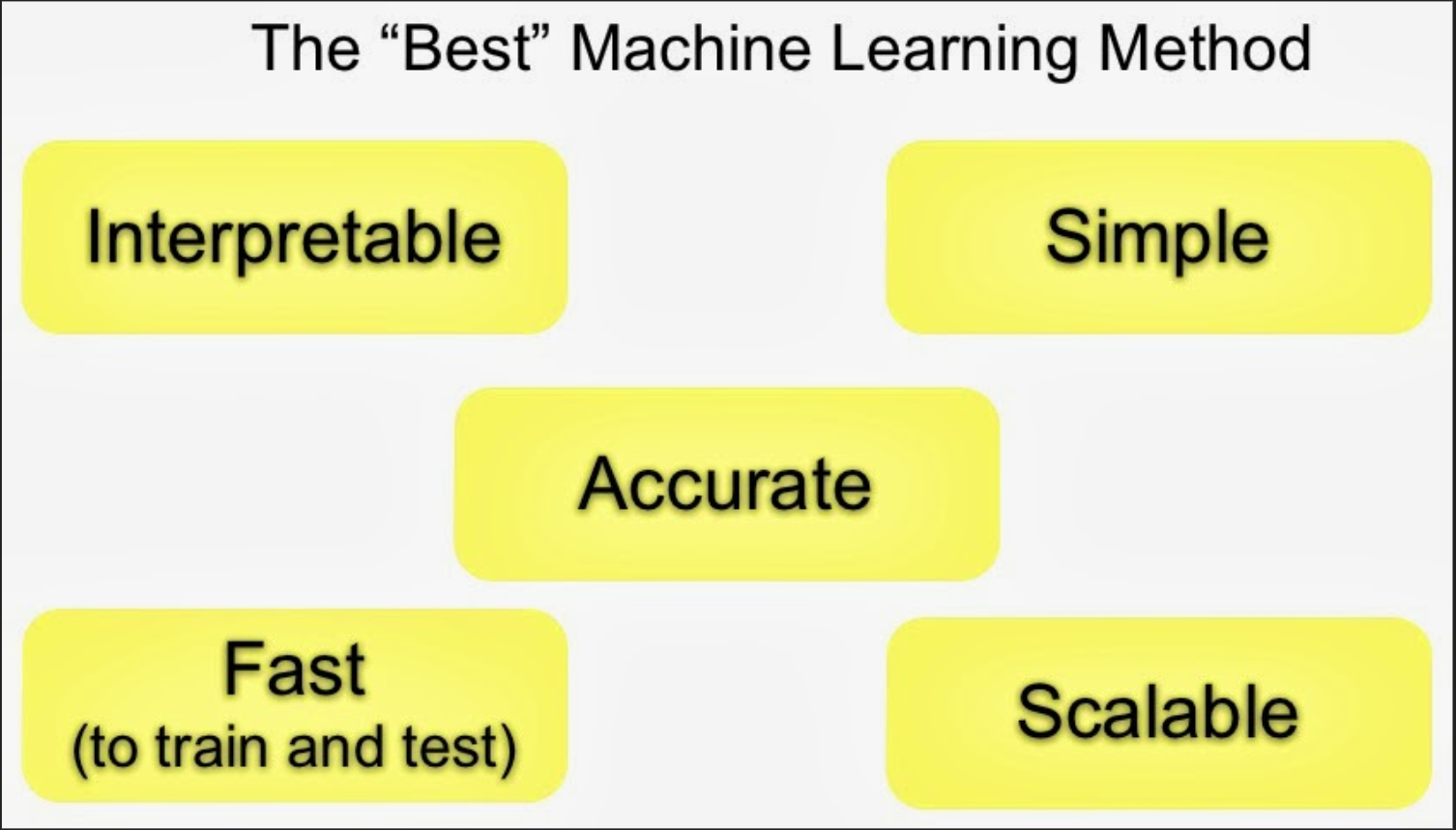
The important tradeoffs are:
- Interpretability versus accuracy
- Speed versus accuracy
- Simplicity versus accuracy
- Scalability versus accuracy
Types of models
There are a few key ideas you should know about that define most regression models you will run into in practice.
- Regression
- Trees
- Ensembling
- Neural Networks
Today we will briefly demonstrate trees.
Trees
Classification and regression trees are an extremely popular approach to prediction. The basic algorithm for a classification tree is the following:
- Start with all variables in one group
- Find the variable/split that best separates the outcomes
- Divide the data into two groups (“leaves”) on that split (“node”)
- Within each split, find the best variable/split that separates the outcomes
- Continue until the groups are too small or sufficiently “pure”
This is an example tree:
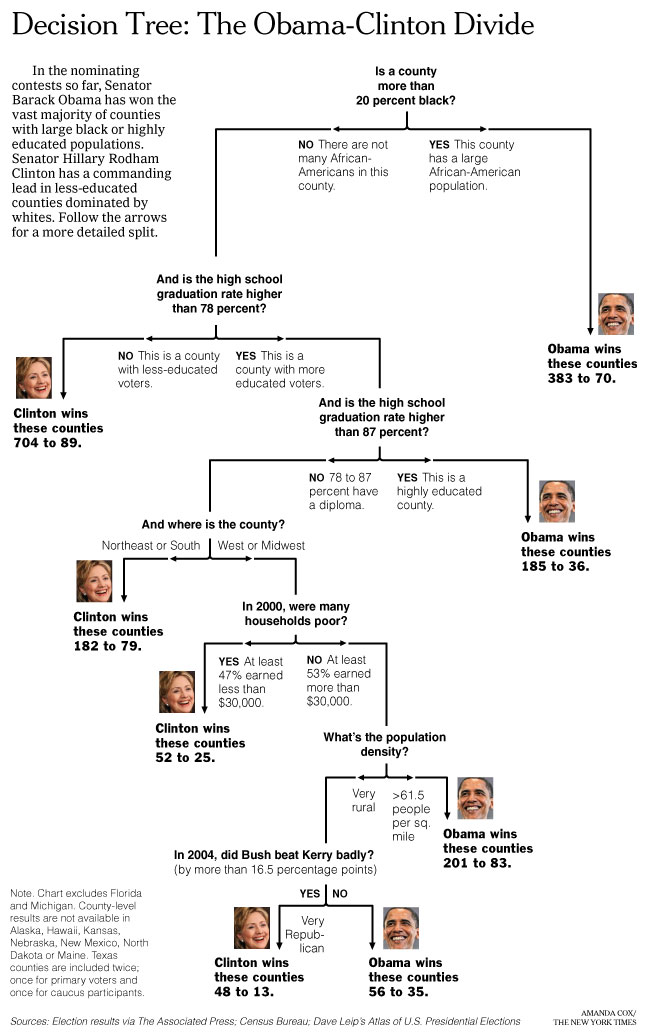
The big question is how to define “best separates the outcomes” in Step 4 of the general algorithm.
For continuous data, you might minimize the residual sum of squares in each group.
For binary data, you might measure misclassification or information gain.
- Strengths - Trees are usually easy to understand and can be fit quickly.
- Weaknesses - Trees have a tendency not to be terribly accurate compared to some other methods and may overfit.
Our example
Based on these plots of a few of the features:
ggplot(train_dat, aes(x=type,y=pixel1)) +
geom_violin() +
theme_minimal() +
scale_y_log10()
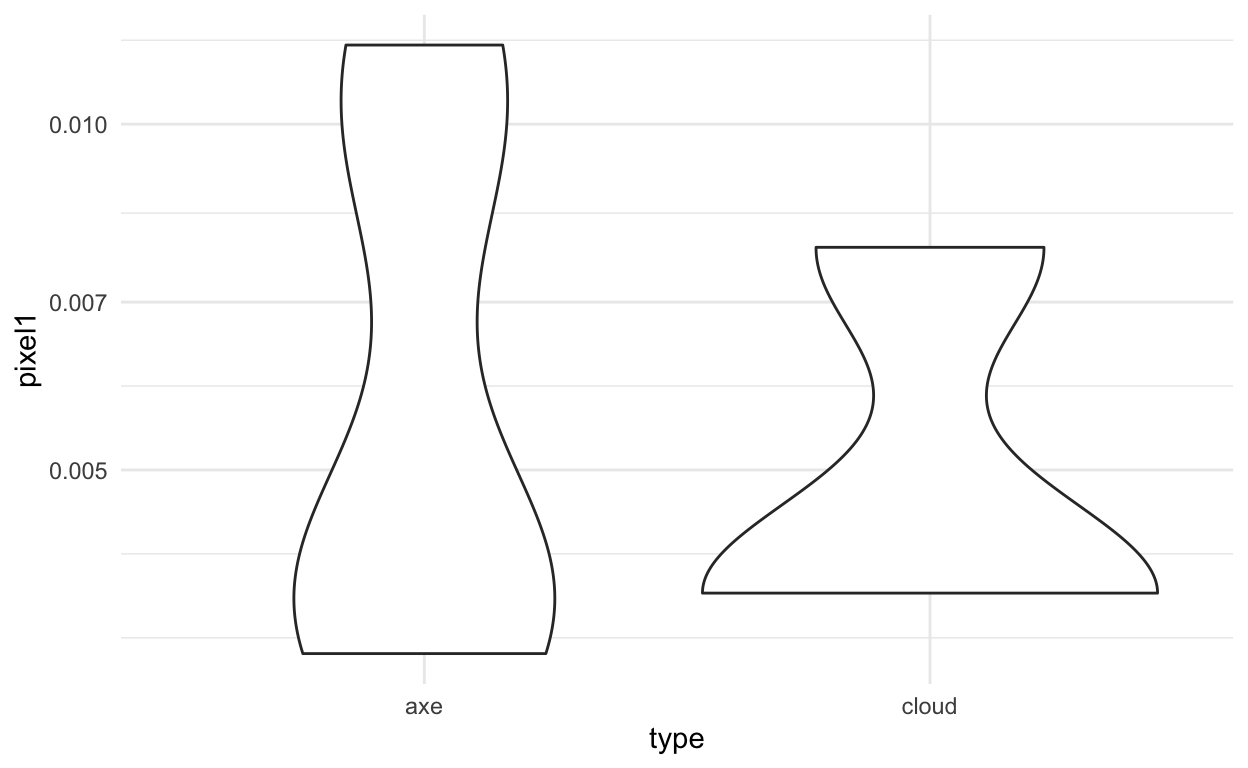
ggplot(train_dat, aes(x=type,y=pixel2)) +
geom_violin() +
theme_minimal() +
scale_y_log10()
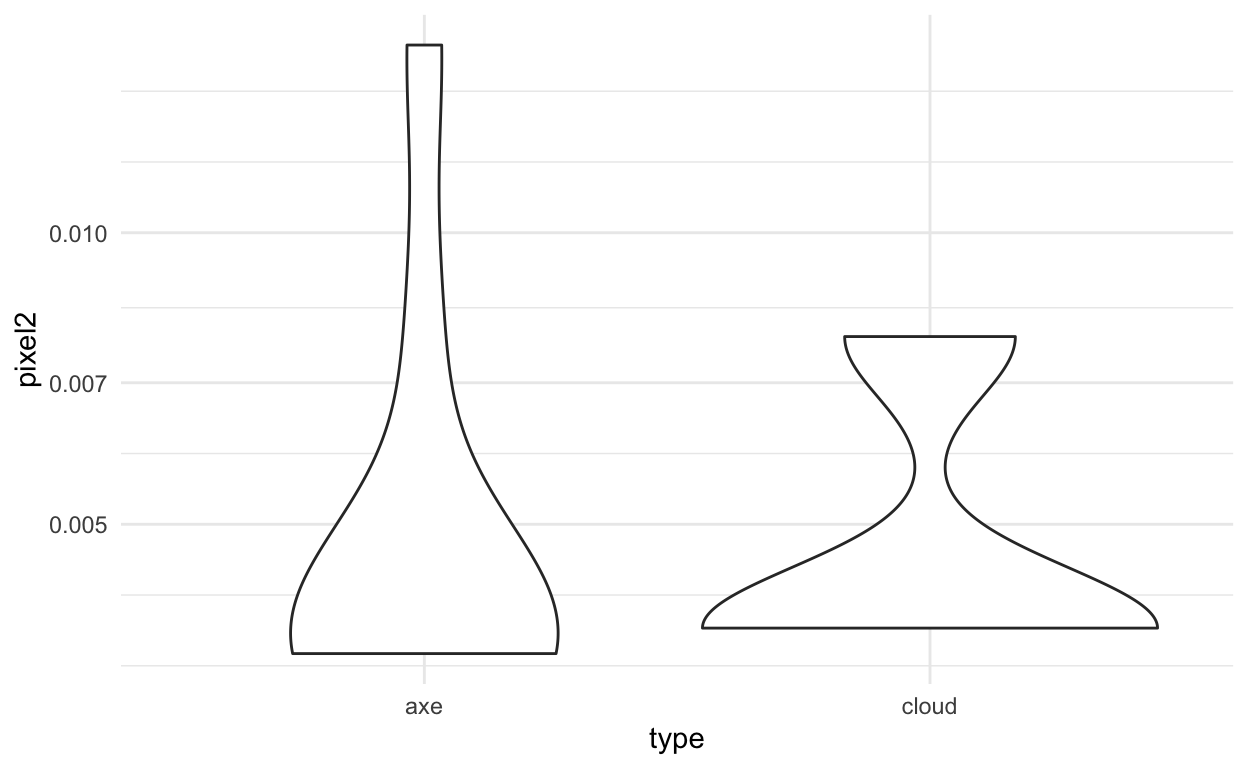
We should be able to do ok for this model fitting. We can fit models using the caret package. The caret package simplifies a lot of model fitting for machine learning. We can use the train command to do this in R.
CART
100 samples
257 predictors
2 classes: 'axe', 'cloud'
No pre-processing
Resampling: Bootstrapped (25 reps)
Summary of sample sizes: 100, 100, 100, 100, 100, 100, ...
Resampling results across tuning parameters:
cp Accuracy Kappa
0.14 0.8385178 0.6751338
0.26 0.7900434 0.5798719
0.54 0.6274736 0.2868931
Accuracy was used to select the optimal model using the
largest value.
The final value used for the model was cp = 0.14.Here, you can see we have reasonable accuracy, this accuracy is estimated using bootstrapping only the training set.
We can look at the final model fit after model selection using the finalModel argument.
mod$finalModel
n= 100
node), split, n, loss, yval, (yprob)
* denotes terminal node
1) root 100 50 axe (0.50000000 0.50000000)
2) pixel246< 0.001953125 73 23 axe (0.68493151 0.31506849)
4) pixel243< 0.001953125 58 9 axe (0.84482759 0.15517241) *
5) pixel243>=0.001953125 15 1 cloud (0.06666667 0.93333333) *
3) pixel246>=0.001953125 27 0 cloud (0.00000000 1.00000000) *You can use the rpart.plot package to visualize what is actually going on here.
rpart.plot(mod$finalModel)
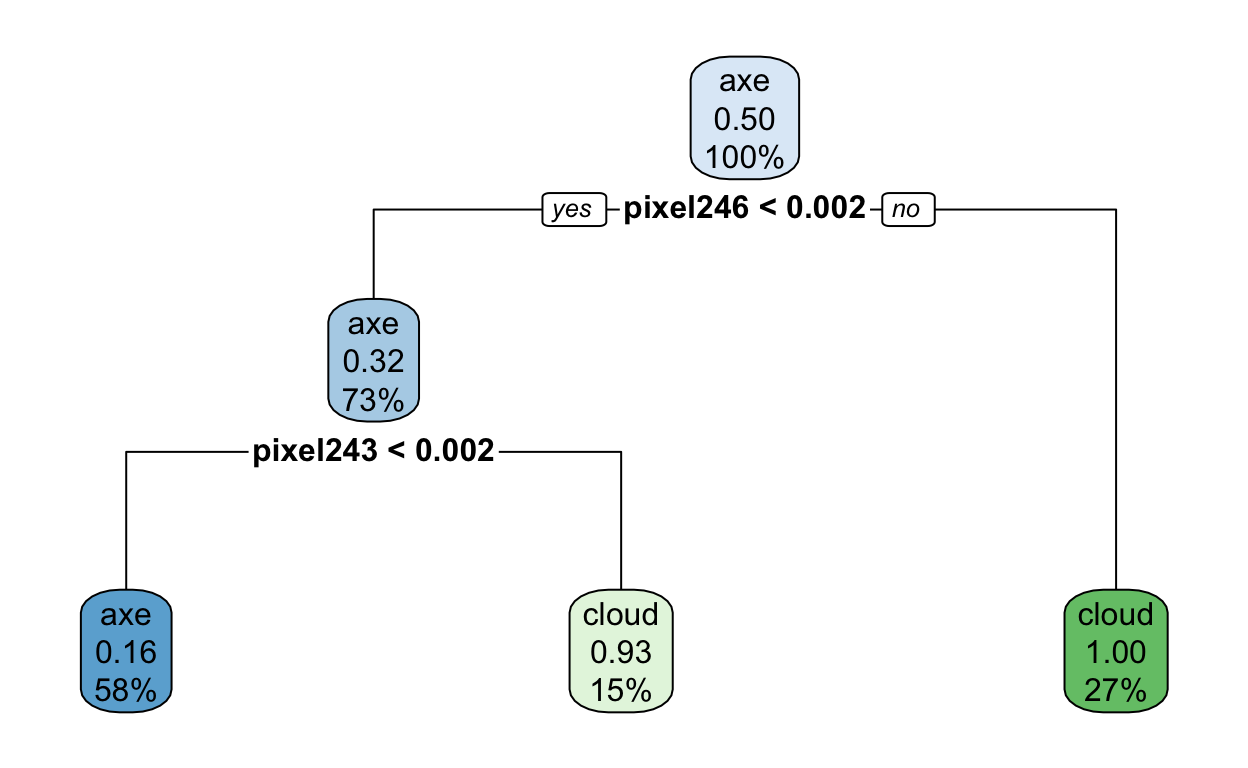
Interesting! I wonder what pixel 246 is?? Can you guess? If not, no worries. Hang tight.
Model evaluation
The last step is model evaluation. A good model evaluation includes the components:
- Evaluation of the model predictions based on the goal you stated at the beginning of the problem.
- Exploratory analysis of predictions to ensure that there are no obvious problems.
- Important: considerations of the practical and ethical consequences of deploying your model.
why is this important?
A while back Amazon developed an AI algorithm for predicting who they should hire. They did a good job of evaluating criteria 1 (above): i.e. they knew they could accurately predict in their training set.
However, they missed criteria 2 (abvoe) i.e. they did not do an exploratory analysis to identify what their model was using to make predictions.
They also did not do a careful job of evaluating the implications of their model in terms of bias.
This led to some major problems. (worth a peek)
back to model evaluation
Before evaluating our model in the test set, we want to understand what is going on with our prediction. This is an active and open area of research: the interpretation of results from black box machine learning algorithms.
We can do this in a couple of ways. One approach that has seen some traction is locally interpretable model agnostic explanations (lime). This approach fits very simple local models to approximate the complicated model in a local neighborhood.
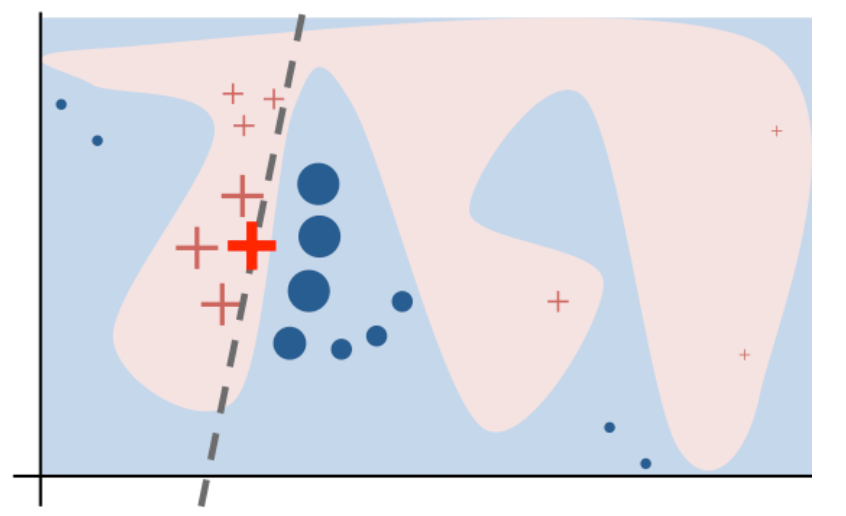
Then for each prediction you can see how much the features are positively or negatively correlated with the complex model near that prediction. To do this, you can use the lime package.
Or you can start looking at the data for individual features.
img_final %>%
ggplot(aes(x=type,y=pixel246)) +
geom_violin() +
theme_minimal() +
scale_y_log10()
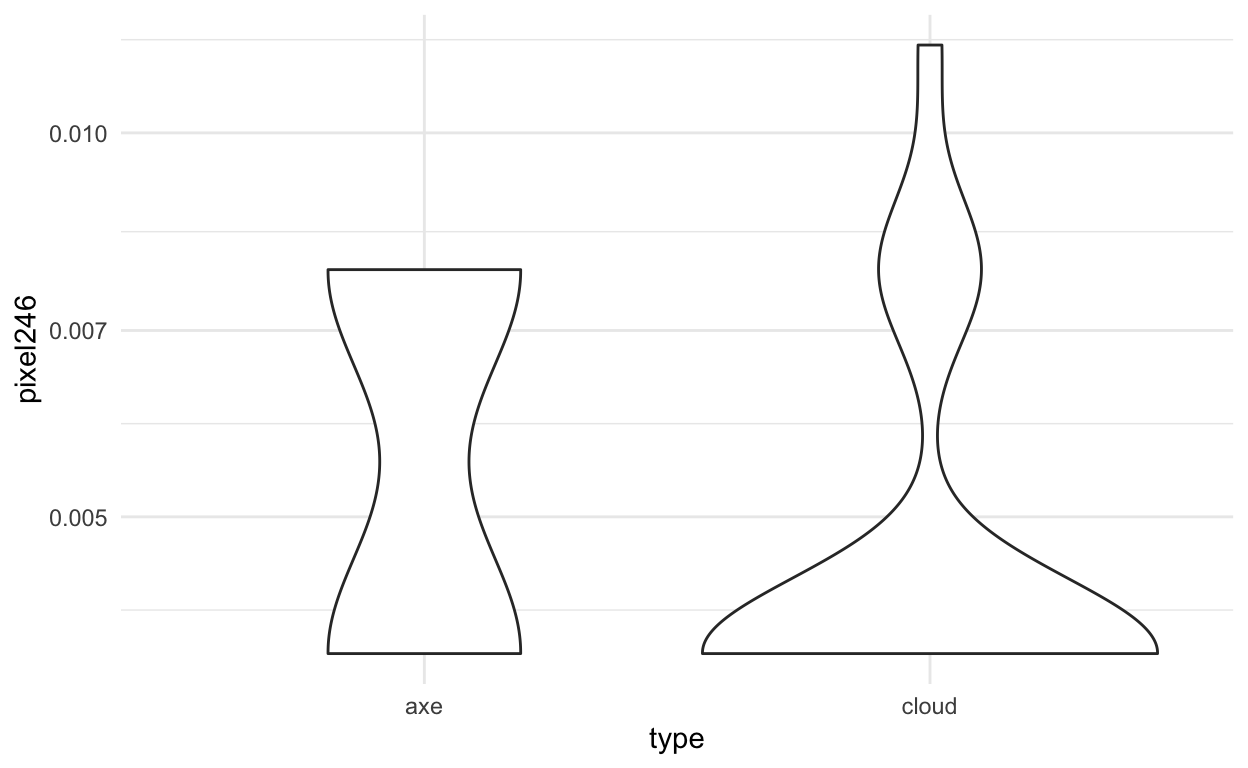
We can also look at where this pixel would be in the image:
expand.grid(x=1:16,y=1:16)[246,]
x y
246 6 16And plot it

We can also figure out which of the images are misclassified and look at them
Let’s look at one of the missed images
missed_imgs = missed_imgs %>%
filter(type=="axe")
rjson::fromJSON(axes_json[[missed_imgs$drawing[1]]]) %>%
parse_drawing() %>%
ggplot(aes(x=x, y=y)) +
geom_path(aes(group = line), lwd=1) +
scale_x_continuous(limits=c(0, 255)) +
scale_y_reverse(limits=c(255, 0)) +
theme_minimal()
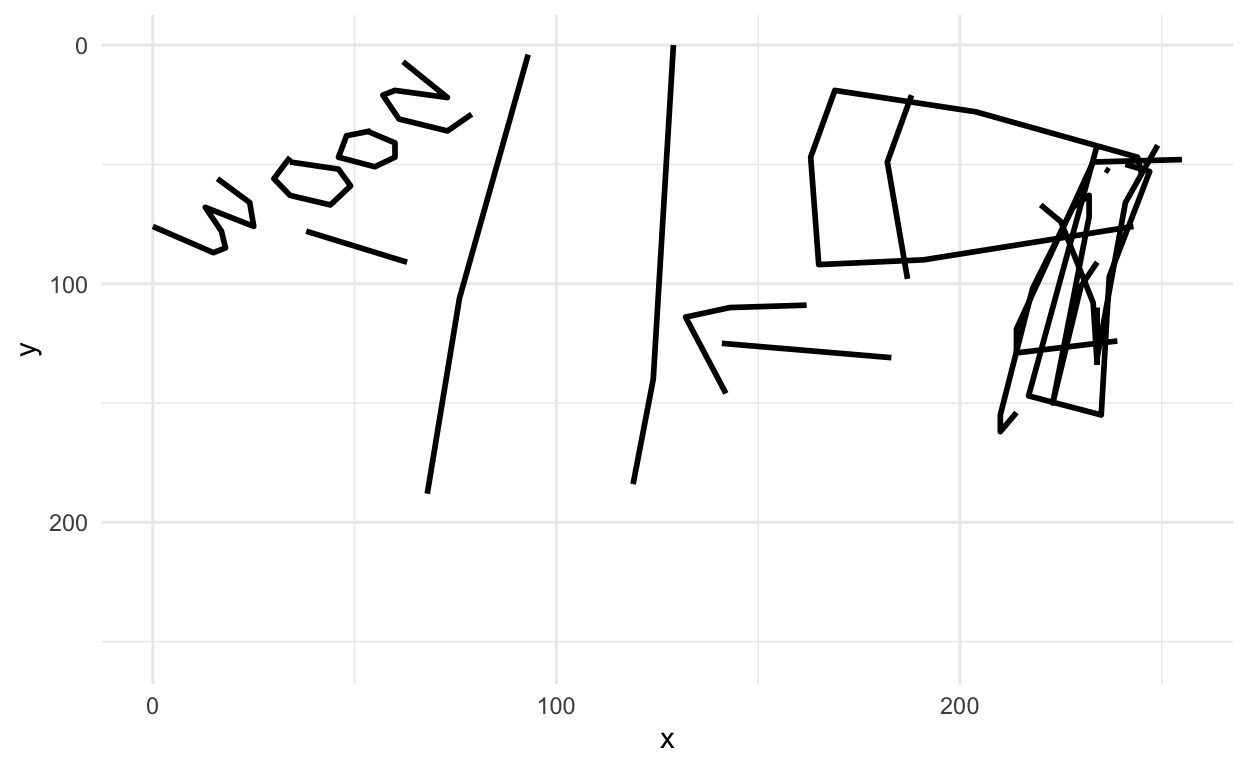
ha! makes sense now
The last step (!!) is to apply the predictions in the test set. You only do this once, but it gives you the best estimate of the out of sample error rate you’d see in practice.
confusionMatrix(factor(test_dat$type), predict(mod,test_dat))
Confusion Matrix and Statistics
Reference
Prediction axe cloud
axe 45 5
cloud 13 37
Accuracy : 0.82
95% CI : (0.7305, 0.8897)
No Information Rate : 0.58
P-Value [Acc > NIR] : 2.857e-07
Kappa : 0.64
Mcnemar's Test P-Value : 0.09896
Sensitivity : 0.7759
Specificity : 0.8810
Pos Pred Value : 0.9000
Neg Pred Value : 0.7400
Prevalence : 0.5800
Detection Rate : 0.4500
Detection Prevalence : 0.5000
Balanced Accuracy : 0.8284
'Positive' Class : axe
This accuracy is usually slightly lower than the accuracy in the training data.
Post-lecture materials
Additional Resources